HashTable与HashMap的区别
- HashMap实现不同步,线程不安全。HashTable线程安全 HashMap中的key-value都是存储在Entry中的。
- 继承不同
Hashtable继承 Dictionary类,而HashMap继承AbstractMappublic
- class Hashtable extends Dictionary implements Mappublic
- class HashMap extends AbstractMap implements Map
- Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
- Hashtable 中, key和value都不允许出现 null值。在HashMap中, null 可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null 。
- 当get()方法返回null 值时,即可以表示HashMap中没有该键,也可以表示该键所对应的值为null 。因此,在 HashMap中不能由get()方法来判断
- HashMap中是否存在某个键,而应该用containsKey()方法来判断。
- 哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值
HashMap
Put方法

在我们的多线程并发情况下 table数组 作为我们共享的一个变量,则有可能会发生线程安全
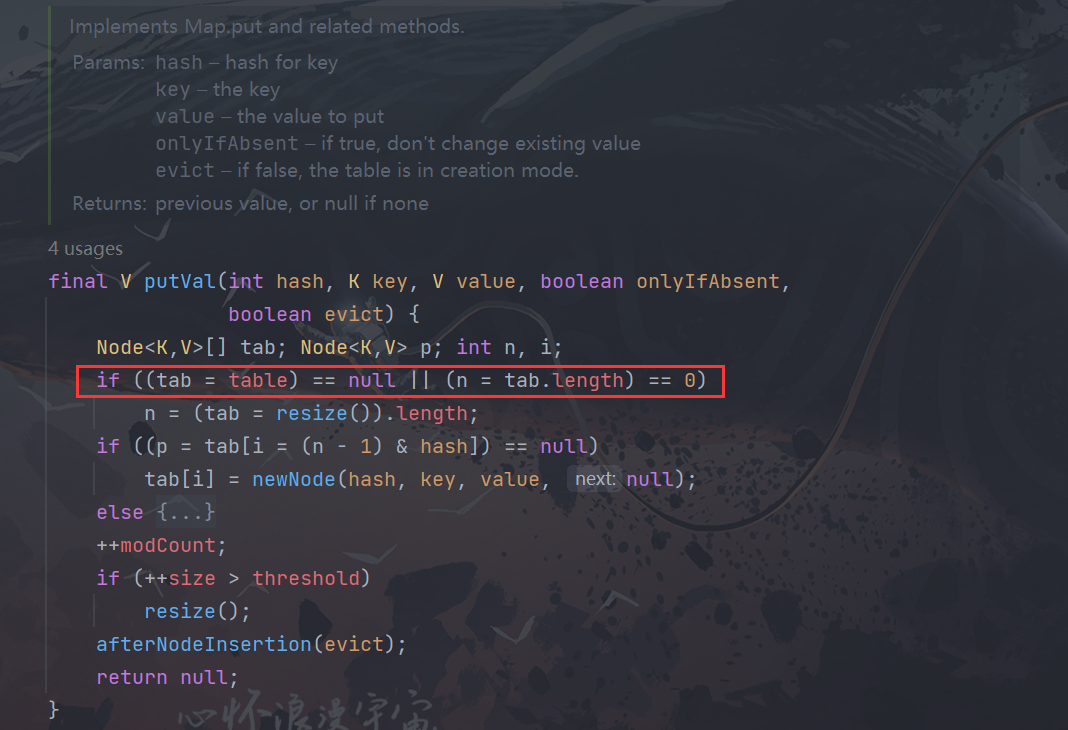

HashMap 1.7
- 数组+链表
- 头插入方式(并发扩容死循环问题)
- 代码写法简单
HashMap 1.8
- 数组+链表+红黑树
- 尾插入方式
- 代码写法高大上
- 红黑树转换
- 数组容量>=64&链表长度>8
- 红黑树节点个数<6转换链表
HashMap的长度为什么是2的幂次方
为了能让HashMap存取高效, 尽量较少碰撞 ,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是”(n - 1) & hash "。(n代表数组长度)。这也就解释了HashMap的长度为什么是2的幂次方。
这个算法应该如何设计呢?
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说hash%length==hash&(length-1)的前提是length是2的n次方;)。"并且采用二进制位操作&,相对于%能够提高运算效率,这就解释了HashMap的长度为什么是2的幂次方。
HashMap 多线程操作导致死循环问题
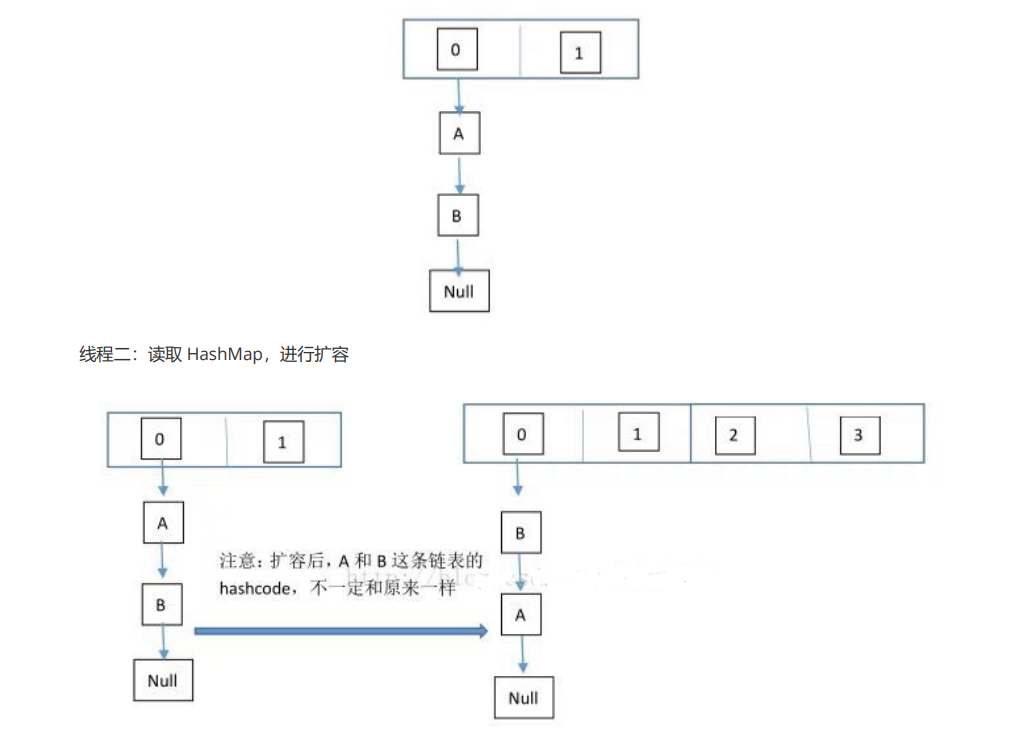
在多线程下,进行 put 操作会导致 HashMap 死循环,原因在于 HashMap 的扩容 resize()方法。由于扩容是新建一 个数组,复制原数据到数组。由于数组下标挂有链表,所以需要复制链表,但是多线程操作有可能导致环形链表。复 制链表过程如下: 以下模拟2个线程同时扩容。
假设,当前 HashMap 的空间为2(临界值为1),hashcode 分别为 0 和 1,在散列地 址 0 处有元素 A 和 B,这时候要添加元素 C,C 经过 hash 运算,得到散列地址为 1,这时候由于超过了临界值,空 间不够,需要调用 resize 方法进行扩容,那么在多线程条件下,会出现条件竞争,模拟过程如下: 线程一:读取到当前的 HashMap 情况,在准备扩容时,线程二介入
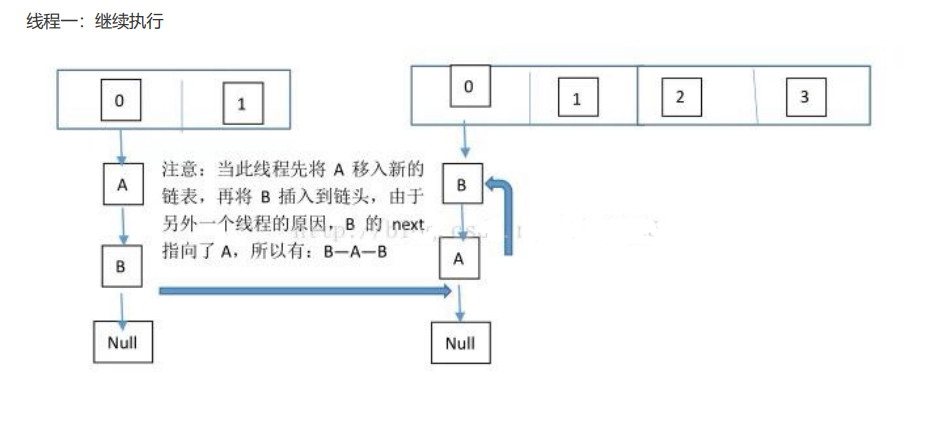
这个过程为,先将 A 复制到新的 hash 表中,然后接着复制 B 到链头(A 的前边:B.next=A),本来 B.next=null, 到此也就结束了(跟线程二一样的过程),但是,由于线程二扩容的原因,将 B.next=A,所以,这里继续复制A,让 A.next=B,由此,环形链表出现:B.next=A; A.next=B
JDK8中HashMap依然会死循环!
jdk1.7版本中多线程同时对HashMap扩容时,会引起链表死循环,尽管jdk1.8修复了该问题,但是同样在jdk1.8版本中多线程操作hashMap时仍然会引起死循环,只是****原因不一样** 。**

1.8是在链表转换树或者对树进行操作的时候会出现线程安全的问题
在多线程下不要使用HashMap,至少jdk8及其以下不要使用,之上版本也建议不要使用。
HashTable


Hashtable 实现了锁的运用,并且拒绝value为空

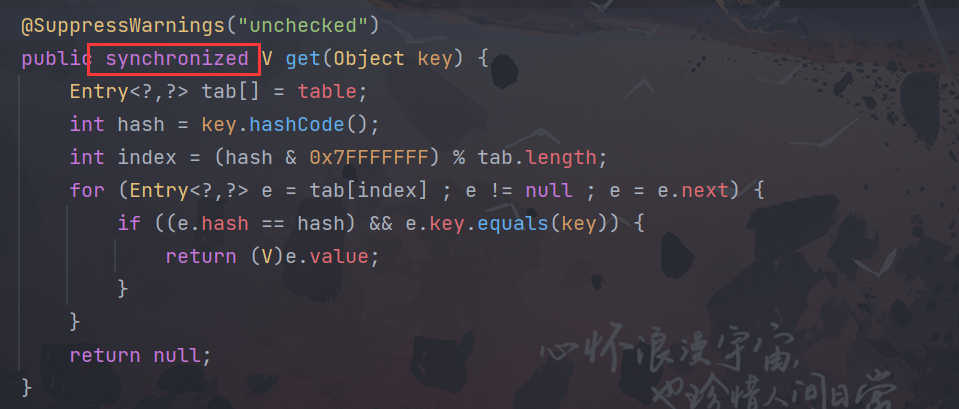
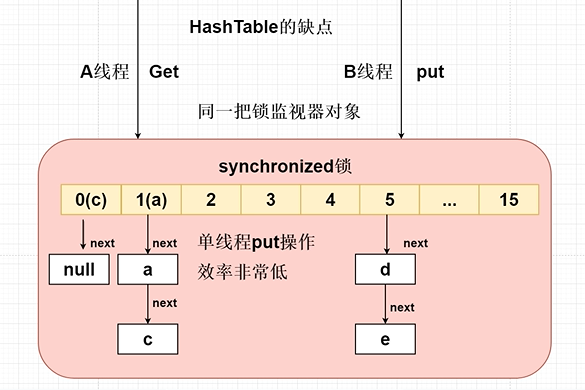
为什么不使用HashTable
- HashTable 底层通过synchronized保证线程安全性问题保证线程安全性问题---加上锁---发生锁的竞争
- HashTable当多个线程在访问get或者put操作的时候会发生this锁的竞争,多个线程竞争锁最终只会有一个线程获取到this锁,获取不到的this锁可能会阻塞等待。|
- 使用传统HashTable保证线程问题,是采用synchronized锁将整个HashTable中的数组锁住,在多个线程中只允许一个线程访问Put或者Get,效率非常低,但是能够保证线程安全问题。
public static void main(String[] args) {
Hashtable<Object, Object> hashtable = new Hashtable<>();
new Thread(new Runnable() {
@Override
public void run() {
hashtable.put("1", "1");
}
}, "线程1").start();
new Thread(new Runnable() {
@Override
public void run() {
hashtable.get("1");
}
}, "线程2").start();
//线程2在获取this锁在做get操作,另外的线程无法访问 get或者put操作
System.out.println("hashtable = " + hashtable);
}ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同
- 底层数据结构
JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟 HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类 似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
- 实现线程安全的方式(重要)
- ① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了 分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁 竞争,提高并发访问率。 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑 树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很 多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构, 但是已经简化了属性,只是为了兼容旧版本;
- ② Hashtable(同一把锁) :使用 synchronized 来保证线程安全, 效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低
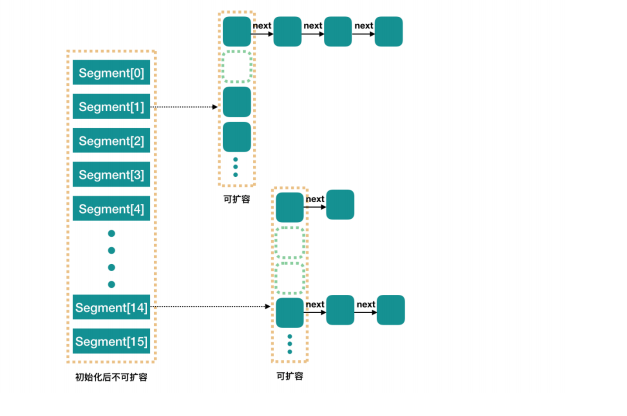
ConcurrentHashMap 1.7
ConcurrentHashMap将一个大的HashMap集合拆分成n多个不同的小的HashTabl(Segment),默认的情况下是分成16个不同的
- 数据结构:数组+segments分段锁+HashEntry链表是实现
- 锁的实现:Lock锁+CAS乐观锁+UNSAFE类
- 扩容实现:支持多个Segment同时扩容
ConcurrentHashMap 1.7版本做写的操作如果多个线程写入的key最终计算落地到不同小的HashTable集合中,就可以实现多线程同时写入key 不会发生锁的竞争。
如果多个线程写入的key最终计算落地到同一个小的HashTable集合中,就会发生锁的竞争。
Put方法锁住的为节点
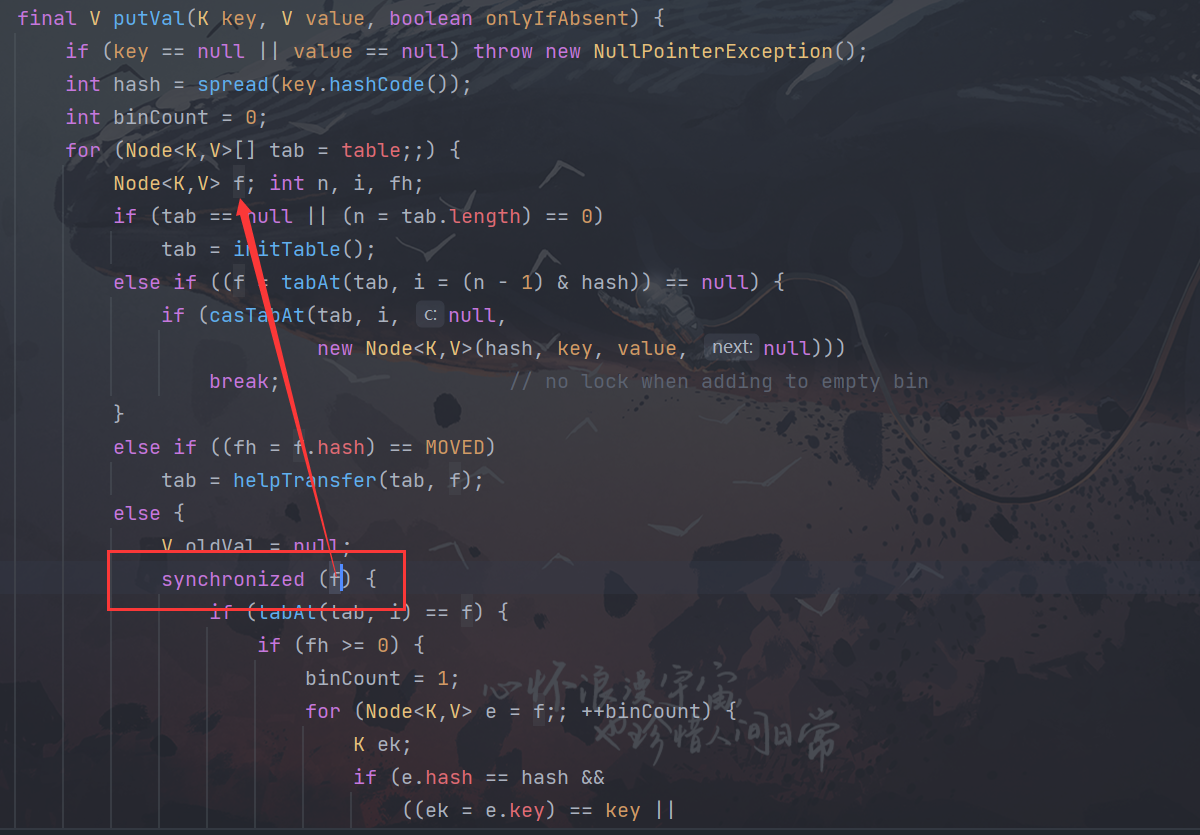
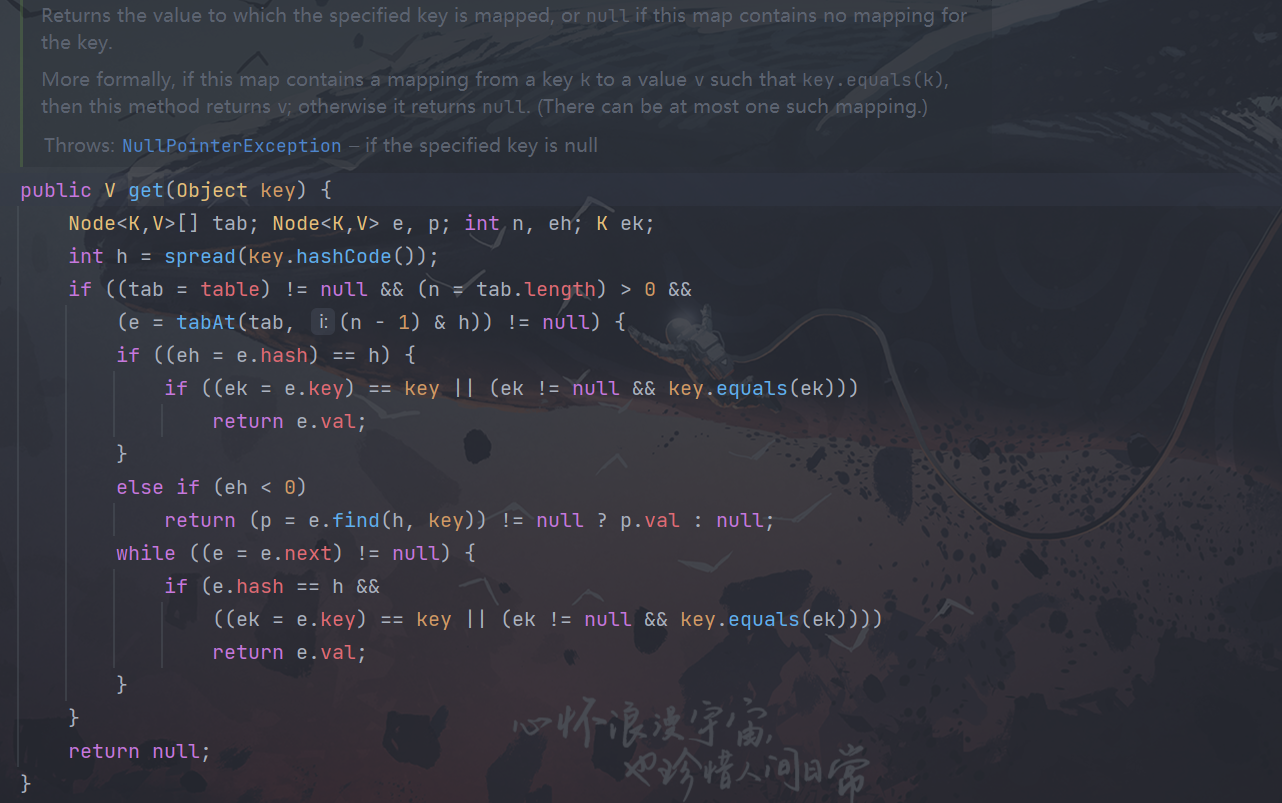
但是在get方法中并无锁的竞争,HashTable 的get方法有锁的竞争
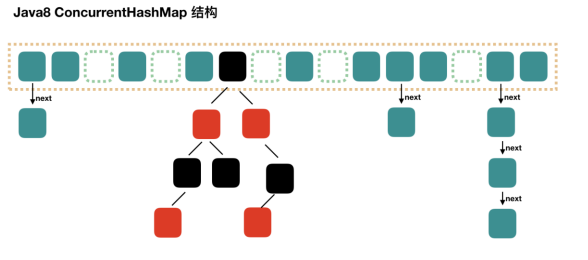
ConcurrentHashMap 1.8
取消了分段锁的设计
纯手写ConcurrentHashMap
ConcurrentHashMap 1.7版本需要计算出2次index值。
- 第一次计算index=计算key存放到具体小的HashTable
- 第二次计算index=计算key存放到具体小的HashTable对应具体数组index位置
ConcurrentHashMap 底层采用分段锁设计将一个大的HashTable线程安全的集合拆分成n多个小的 HashTable集合,默认初始化16个小的HashTable集合。
如果同时16个线程最终计算index值 落地到不同的小的HashTable集合不会发生锁的竞争,同时可以支持16个线程访问ConcurrentHashMap写的操作,效率非常高。
import java.util.Hashtable;
/**
* @author Wcy
* @Date 2022/10/2 13:23
*/
public class MyConcurrentHashMap<K,V> {
/**
* ConcurrentHashMap如何设计
* ConcurrentHashMap的默认容量?默认容量是16
* 提前创建固定数组容量大小的 小的HashTable集合
*/
private Hashtable<K, V>[] hashtables;
public MyConcurrentHashMap() {
// 初始化16个小的HashTable集合
hashtables = new Hashtable[16];
for(int i = 0; i < hashtables.length; i++) {
hashtables[i] = new Hashtable<>();
}
}
/**
* put方法
* @param key
* @param value
*/
public void put(K key, V value) {
// 1.根据key的hashcode值,计算出在哪个小的HashTable集合中
int index = key.hashCode() % hashtables.length;
// 2.将key和value存储到对应的小的HashTable集合中
hashtables[index].put(key, value);
}
/**
* get方法
* @param key
* @return value
*/
public V get(K key) {
// 1.根据key的hashcode值,计算出在哪个小的HashTable集合中
int index = key.hashCode() % hashtables.length;
// 2.将key和value存储到对应的小的HashTable集合中
return hashtables[index].get(key);
}
public static void main(String[] args) {
MyConcurrentHashMap<String, String> myConcurrentHashMap = new MyConcurrentHashMap<>();
myConcurrentHashMap.put("1", "1");
myConcurrentHashMap.put("2", "2");
System.out.println(myConcurrentHashMap.get("1"));
System.out.println(myConcurrentHashMap.get("2"));
}
}
此处评论已关闭