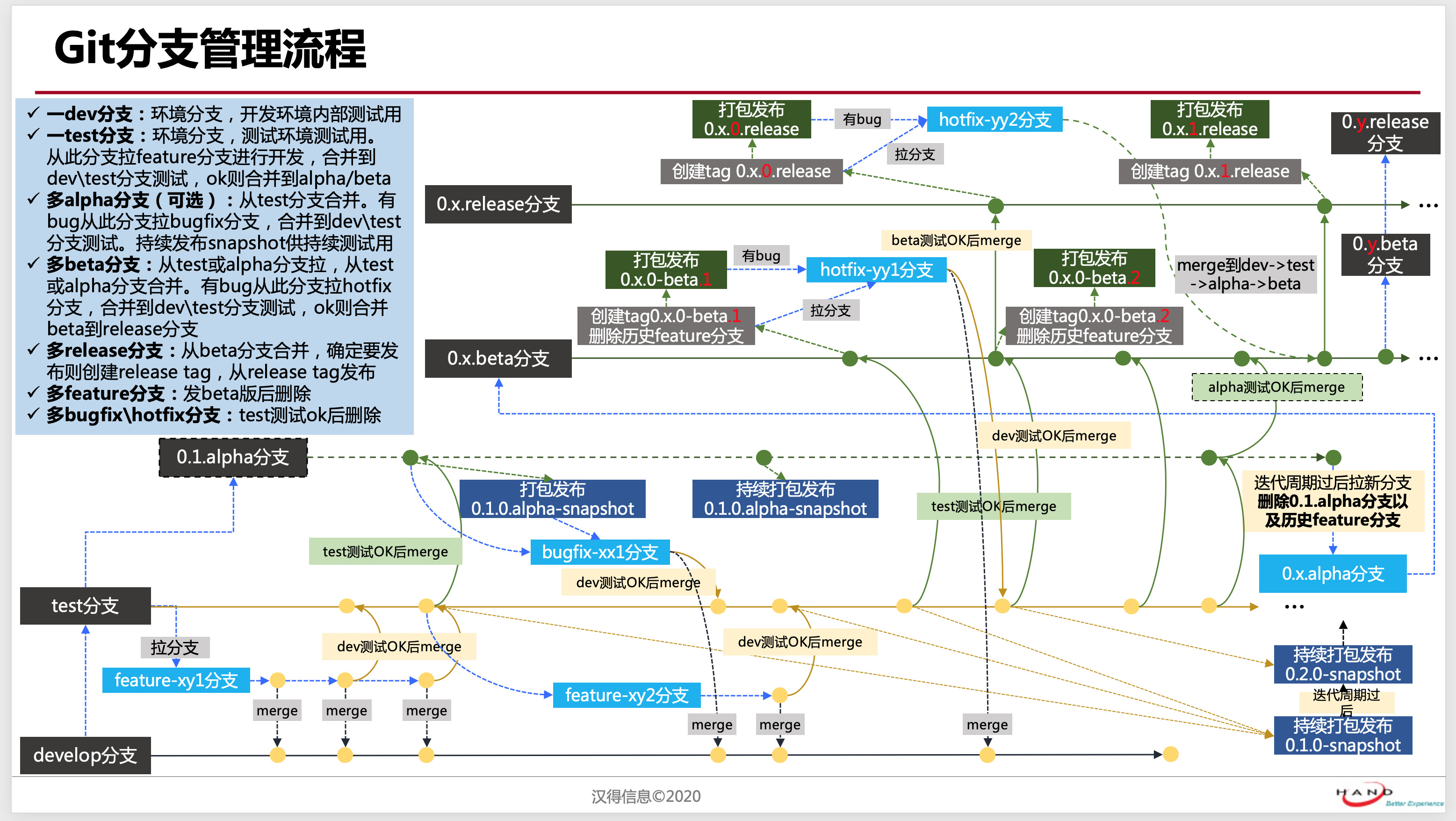
分支管理规范
目前比较流行的分支管理模型有三个,即GitFlow、GitLabFlow、GitHubFlow。
GitFlow
该模型中存在两种长期分支:master和develop。
master 中存放对外发布的版本,只有稳定的发布版本才会合并到 master 中
develop用于日常开发,存放最新的开发版本
也存在三种临时分支:feature , hotfix, release
- feature 分支是 为了 开发 某个特定功能 ,从 develop 分支中切出,开发完成后合并到 develop 分支中。
- hotfix 分支是 修复发布后发现的Bug 的分支, 从 master 分支中切出,修补完成后再合并到 master 和 develop 分支。
- release 分支指 发布稳定版本前使用的预发布分支 ,从develop分支中切出, 预发布完成后,合并到 develop 和 master 分支中。
优点:
- feature分支使开发代码隔离,可以独立的完成开发、构建、测试
- feature 分支开发周期长于release时,可避免未完成的feature进入生产环境
缺点:
- 无法支持持续发布。
- 过于复杂的分支管理,加重了开发者的负担,使开发者不能专注开发。
GitHubFlow
GitHubFlow 分支模型只存在一个 master主分支,日常开发都合并至 master , 永远保持其为最新的代码且随时可发布的 。
- 在需要添加或修改代码时, 基于 master 创建分支,提交修改。
- 创建 Pull Request ,所有人讨论和审查你的代码。
- 然后部署到生产环境中进行验证。
- 待验证通过后合并到 master 分支中。
这个分支模型的优势在于简洁易理解,将 master**作为核心的分支,代码更新持续集成至master上。根据目前收集到的反应来看,得到了更多的好评,认为 GitHubFlow 分支模型更加轻便快捷。**
GitLabFlow
GitLabFlow 是GitFlow和GitHubFlow的结合,它吸取了两者的优点,既有适应不同开发环境的弹性,又有单一主分支的简单和便利。
该模型采取上游优先的原则,即只存在一个**master**主分支,它是所有分支的上游。只有上游分支采纳的变动才能应用到其他分支。
- 对于持续发布的项目,建议在 master 之外再建立对应的环境分支,如预生产环境 pre-production ,生产环境**production**。
- 对于版本发布的项目,建议基于 master 创建稳定版本对应的分支,如 stable-1 , stable-2 。
平台分支管理
多种分支类型,主要流程如下:
分支命名规约
| 前缀 | 含义 |
|---|---|
| **-test | 测试分支,验证后可直接发布的版本 |
| **-beta | 用于发布beta版本分支 |
| **-release | 用于发布正式稳定版分支 |
| develop | 开发主分支,最新的代码分支 |
| feature-** | 功能开发分支 |
| bugfix-** | 未发布bug修复分支 |
| hotfix-** | 已发布bug修复分支 |
核心原则:
1、版本发布是一个递进的过程
2、每个发布的特性或bug修需要进行测试再进行发布
3、小版本仅仅修复bug或仅改版本号进行透明升级的特性
GIT 提交命名规约
除了分支的名称需要规范,提交的命名也同样如此,需要团队共同遵守。
格式为 : [操作类型] 操作对象名称,如 [ADD] readme.md ,代表增加了readme描述文件。
常见的操作类型有:
- [IMP] 提升改善正在开发或者已经实现的功能
- [FIX] 修正BUG
- [REF] 重构一个功能,对功能重写
- [ADD] 添加实现新功能
- [REM] 删除不需要的文件
版本号规范
版本格式:主版本号.次版本号.修订号,版本号递增规则如下
1.主版本号:当你做了 不兼容的 API 修改 。
2.次版本号:当你做了 向下兼容的功能性新增 。
3.修订号: 当你做了 向下兼容的问题修正 。
先行版本号及版本编译信息可以加到“主版本号.次版本号.修订号”的后面,作为延伸。
需求与代码关联
可以通过 Issue 创建分支,或者创建分支时选择关联的 Issue,通过这种方式将需求与代码进行关联。
这样,我们可以追溯到一个用户故事对应了哪些分支,哪几个提交, 甚至出现了一些 BUG,可以找到是哪个分支提交的,当初为了发布XXX新的需求,不仅如此,我们通过需求与代码分支关连,能够查看到哪些需求已经部署到了测试环境,那些需求已经部署到了正式环境,以及从业务到代码的整个链条的统计分析。
版本号信息
- alpha :内部测试版。α是希腊字母的第一个,表示最早的版本,一般用户不要下载这个版本,这个版本包含很多BUG,功能也不全,主要是给开发人员和测试人员测试和找BUG用的。
- beta :公开测试版。β是希腊字母的第二个,顾名思义,这个版本比alpha版发布得晚一些,主要是给“部落”用户和忠实用户测试用的,该版本任然存在很多BUG,但是相对alpha版要稳定一些。这个阶段版本的软件还会不断增加新功能。如果你是发烧友,可以下载这个版本。
- RC (Release Candidate):候选版本。该版本又较beta版更进一步了,该版本功能不再增加,和最终发布版功能一样。这个版本有点像最终发行版之前的一个类似预览版,这个的发布就标明离最终发行版不远了。作为普通用户,如果你很急着用这个软件的话,也可以下载这个版本。
- stable :稳定版。在开源软件中,都有stable版,这个就是开源软件的最终发行版,用户可以放心大胆的用了。
- RELEASE :最终版本。在前面版本的一系列测试版之后,终归会有一个正式版本,是最终交付用户使用的一个版本。该版本有时也称为标准版。一般情况下,Release不会以单词形式出现在软件封面上,取而代之的是符号(R)。
命名规约
服务配置
在开发过程中需要用到很多配置,为了保持可读性和维护性,配置段不宜过多,控制在4~5段即可,其中第一段为固定段(项目名称):例如 hzero,第二段为服务/组件段,第三、四段为规则段,最后一段为配置值。
例:系统启动是否开启Redis初始化的配置, hzero:platform:init-cache:false
值集数据配置
- 按功能划分(仅本功能使用)服务模块+功能+用途,(编码规则字段类型)
如:HPFM.CODE_RULE.FIELD_TYPE
- 按服务划分(服务内可通用)服务模块+用途,(标识)
如:HPFM.FLAG
- 按全局划分(所有服务通用)HPFM(平台服务) 下的服务级值集,其他服务都可使用
如:HPFM.TEXT_TYPE
- 值集使用说明 :
由于值集存在共用情况,在创建值集时需要先去判断是否已登记存在,如果存在则与负责人(技术设计者和业务负责人)沟通是否可以直接使用,避免重复造轮子和引起混乱。
值集视图配置
- 命名规则参考值集命名(1、2、3)
- 注意: **不存在LOV应用配置全局划分情况,每个微服务的LOV应用配置都是服务下,前端开发引用时需要特别注意,不能跨服务调用,以避免后续拆分造成问题。**
编码规则配置
- 按功能划分(仅本功能使用)
服务模块+功能+用途,如:**HPFM.USER.USERNAME**(平台服务.用户管理.用户名) - 按服务划分(服务内可通用)
服务模块+用途,如:**HIMP.BATCH_ID**(导入服务.批次号)
*以上规范注意事项****
编码的代码统一大写
定义代码时尽量用英文或英文简称,并且不宜过长
描述尽量表达清楚
每个段之间用点号“.”隔开
*一段中如果存在多个单词,用下划线 _ 隔开
消息模板代码
- 按功能划分(仅本功能使用)
服务模块+功能+用途,如:**HIAM.USER.REGISTER**IAM服务.用户.注册成功通知) - 按服务划分(服务内可通用,HPFM服务下的服务级全局可通用)
服务模块+用途,如:**HPFM.VERIFICATION_CODE**(平台服务.验证码)
*以上规范注意事项****
编码的代码统一大写
定义代码时尽量用英文或英文简称,并且不宜过长
描述尽量表达清楚
每个段之间用点号“.”隔开
*一段中如果存在多个单词,用下划线 _ 隔开
多语言描述维护
多语言标签
- 按功能划分(仅本功能使用)服务模块+功能+用途
如:**hpfm.user.age**(年龄)
- 按服务划分(服务内可通用)服务+用途
如:**hiam.common.menu**(菜单)
- 按全局划分(所有服务通用)HPFM(平台服务)下的服务级值集,其他服务都可直接使用,
如:**hpfm.common.userName**(用户名)
返回消息
- 按功能划分(仅本功能使用)
服务模块+类型+功能+用途,如:**hpfm.error.user.ageNull**(年龄不能为空) - 按服务划分(服务内可通用)
服务模块+类型+用途,如:**hpfm.error.menuNameNull**(菜单名称不能为空) - 按全局划分(所有服务通用)
HPFM(平台服务)、HIAM(身份权限服务)下的服务级值集,其他服务都可直接使用,如:**hpfm.error.noAuth**(没有操作权限,请联系管理员)
*多语言规范注意事项****
快速编码的代码统一小写
定义代码时尽量用英文或英文简称,并且不宜过长
描述尽量表达清楚
每个段之间用点号“.”隔开
*一段中如果存在多个单词,使用 驼峰 方式
多语言描述, 一二段 对应prompt_key, 三四段 对应prompt_code
返回消息,第二段的类型只能是 error , info , warn ,为了与界面返回消息配置对应,请不要随意发挥
其他命名原则
- 为了基础定义数据统一规范,也便于按模块或服务进行数据迁移和选配安装,系统中的所有基础定义的编码均建议按照统一规范进行管理
- 除上述说明到的以外,还有其他的一些功能,如消息邮箱账户配置、接口注册配置等,均参考**服务简码.功能.其他属性**命名风格
项目规约
命名规范
- 项目从大到小可分为产品、服务、组件,产品以产品名称命名,如 **hzero、oa、srm**。
- 一个产品下划分多个服务,命名规则:产品名-模块名,如 **hzero-platform、oa-contract**。
- 如果产品下有组件,命名格式:产品名-boot-组件名,如 **hzero-boot-platform**。
GVA的定义
定义 GAV 遵从以下规则:
- GroupID 格式: org.[组织/BU].[子业务线],最多 4 级
正例: org.hzero 或 org.hzero.boot - ArtifactID 格式:产品线名-模块名。语义不重复不遗漏,先到中央仓库去查证一下。
正例: hzero-platform / hzero-mdm / hzero-boot-common - Version :初始化版本定义为**0.1.0-SNAPSHOT**
依赖规范
强制要求
- 二方库版本号命名方式:主版本号.次版本号.修订号
- 主版本号: 产品方向改变, 或者大规模 API 不兼容, 或者架构不兼容升级。
- 次版本号: 保持相对兼容性,增加主要功能特性, 影响范围极小的 API 不兼容修改。
- 修订号: 保持完全兼容性, 修复 BUG、 新增次要功能特性等。
说明: 以** 0.1.0-SNAPSHOT 作为初始化开发版本,并在后续的每次发行时递增次版本号。当软件被用于正式环境,起始版本号为 1.0.0 **版。正式发布的类库必须先去中央仓库进行查证,使版本号有延续性, 正式版本号不允许覆盖升级。如当前版本: 1.3.3, 那么下一个
合理的版本号: 1.3.4 或 1.4.0 或 2.0.0
- 线上应用不要依赖 SNAPSHOT 版本(安全包除外)。
说明: 不依赖 SNAPSHOT 版本是保证应用发布的幂等性。另外,也可以加快编译时的打包构建。 - 二方库的新增或升级,保持除功能点之外的其它 jar 包仲裁结果不变。如果有改变,
必须明确评估和验证, 建议进行** dependency:resolve 前后信息比对,如果仲裁结果完全不一致,那么通过 dependency:tree 命令,找出差异点,进行**排除 jar 包。 - 二方库里可以定义枚举类型,参数可以使用枚举类型,但是接口返回值不允许使用枚举类型或者包含枚举类型的 POJO 对象。
- 依赖于一个二方库群时,必须定义一个统一的版本变量,避免版本号不一致。
说明: 依赖 springframework-core,-context,-beans,它们都是同一个版本,可以定义一个变量来保存版本: ${spring.version},定义依赖的时候,引用该版本。 - 禁止在子项目的 pom 依赖中出现相同的 GroupId,相同的 ArtifactId,但是不同的Version。
说明: 在本地调试时会使用各子项目指定的版本号,但是合并成一个 war,只能有一个版本号出现在最后的 lib 目录中。 可能出现线下调试是正确的,发布到线上却出故障的问题。
推荐
- 所有 pom 文件中的依赖声明放在**dependencies**语句块中
- 所有版本仲裁放在**dependencyManagement**语句块中。
说明:
dependencyManagement里只是声明版本,并不实现引入,因此子项目需要显式的声明依赖, version 和 scope 都读取自父 pom。而 dependencies 所有声明在主 pom 的 dependencies里的依赖都会自动引入,并默认被所有的子项目继承。**
- 二方库不要有配置项,最低限度不要再增加配置项。
- 为避免应用二方库的依赖冲突问题,二方库发布者应当遵循以下原则:
- 精简可控原则。移除一切不必要的 API 和依赖,只包含 Service API、必要的领域模型对象、 Utils 类、常量、枚举等。如果依赖其它二方库,尽量是** provided **引入,让二方库使用者去依赖具体版本号; 无 log 具体实现,只依赖日志框架。
- 稳定可追溯原则。每个版本的变化应该被记录,二方库由谁维护,源码在哪里,都需要能方便查到。除非用户主动升级版本,否则公共二方库的行为不应该发生变化。
应用分层
DDD 代码架构
大的层次上分为四层
- api:接口层,主要负责与外部进行交互,比如一些Restful API、RMI等,这一层主要包括 Facade、DTO还有一些Assembler。
- app:应用层,主要组件就是 Service 服务,但不是简单的DAO层的包装,在领域驱动设计的架构里面,Service层只是一层很“薄”的一层,它内部并不实现任何逻辑,只是负责协调和转发、委派业务动作给更下层的领域层。
- domain:领域层,是领域模型系统的核心,负责维护面向对象的领域模型,几乎全部的业务逻辑都会在这一层实现。内部主要包含Entity(实体)、ValueObject(值对象)、Domain Event(领域事件)和 Repository(仓储)等多种重要的领域组件。
- infra:基础设施层,主要为 api、app 和 domain 三层提供支撑。所有与具体平台、框架相关的实现会在 infra 中提供,避免三层特别是 Domain 层掺杂进这些实现,从而“污染”领域模型。infra 中最常见的一类设施是对象持久化的具体实现、外部系统交互、消息队列等中间件的操作等。
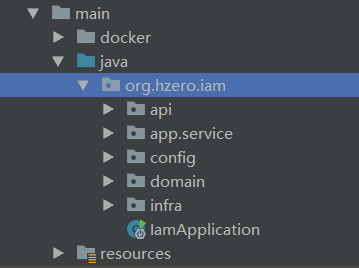
api 层
- controller:提供资源服务,XxxController.java
- dto:数据传输对象,XxxDTO.java,对于一些复杂页面需要多个实体组合时,可使用DTO对象来传输数据。
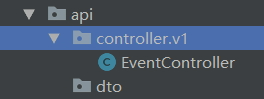
app 层
- service:应用服务,XxxService.java,应用服务里进行事务控制,流程调度
- service.impl:应用服务实现,XxxServiceImpl.java
- assembler:DTO组装器,XxxAssembler.java,复杂DTO的组装,简单的直接使用Entity即可
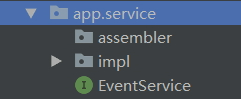
domain 层
- entity:实体对象,与表做映射,具备一些简单的自治的业务方法
- service:领域服务,命名一般按提供的业务功能命名,通常用于封装一个领域内的复杂业务逻辑,简单的业务逻辑在 app 层完成即可,不需要领域层。
- repository:资源库接口,XxxRepository.java,提供数据资源的操作方法,如数据库增删改查、Redis增删改查等,查询操作建议写到 repository 内。
- vo:值对象,XxxVO.java,领域内用到的数据封装,对于一些没有实体对象的数据对象但又在领域中用到,使用值对象封装

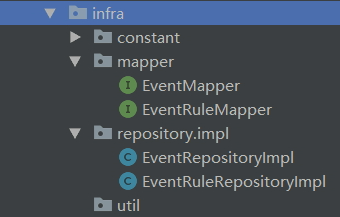
infra 层
- mapper:Mapper接口,XxxMapper.java
- repository.impl:资源库实现,XxxRepositoryImpl.java,业务一定不要侵入到这里
- constant:常量
- util:工具
最简单的DDD架构
至少需要包含如下的结构,将业务和流程分开,应用服务专注用例调度,反应用户故事;领域对象/服务专注核心业务。整个模块通用的放到基础设施层,资源库和外部服务实现也放到基础设施层,屏蔽实现细节。
复制
└─src
├─main
│ ├─java
│ │ └─com
│ │ └─hand
│ │ └─<module>
│ │ ├─api
│ │ │ ├─controller
│ │ │ │ └─v1
│ │ │ │ └─XxxController.java
│ │ │ └─dto
│ │ │ └─XxxDTO.java
│ │ │
│ │ ├─app
│ │ │ └─service
│ │ │ ├─XxxService.java
│ │ │ └─impl
│ │ │ └─XxxServiceImpl.java
│ │ │
│ │ ├─domain
│ │ │ ├─entity
│ │ │ │ └─Xxx.java
│ │ │ └─repository
│ │ │ └─XxxRepository.java
│ │ │
│ │ └─infra
│ │ ├─mapper
│ │ │ └─XxxMapper.java
│ │ └─repository
│ │ └─impl
│ │ └─XxxRepositoryImpl.java
│ │
│ └─resources
│
└─test规范检查
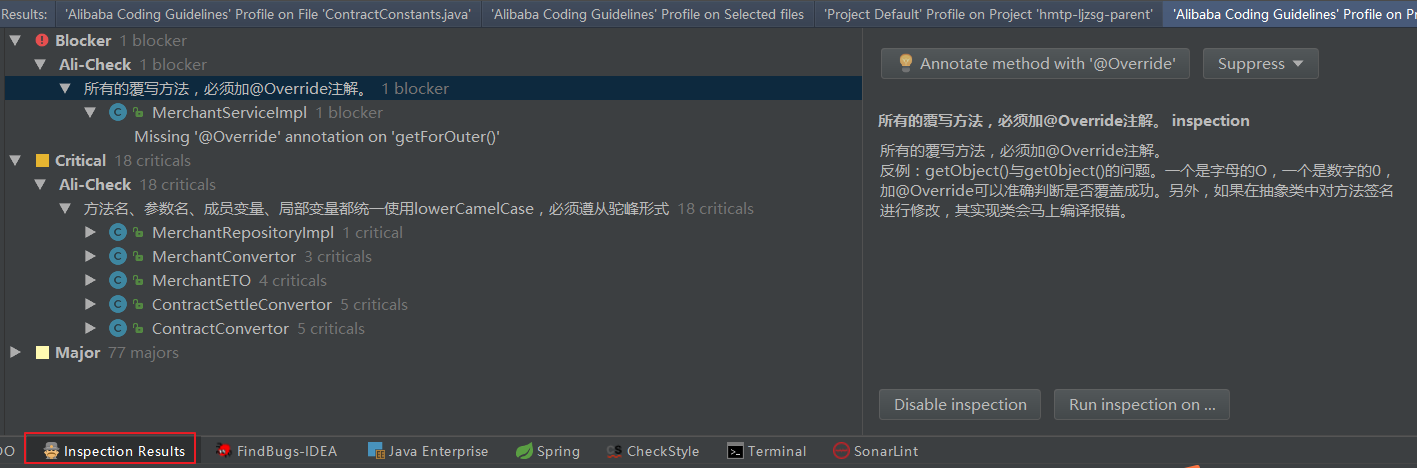
IDEA 开启阿里巴巴规范检查
1、 安装插件 Alibaba Java Coding Guidelines
2、使用插件分析代码
3、工具类绿色按钮扫描代码,蓝色按钮开启/关闭实时检测
4、扫描之后可以看到对应的分析结果以及对应的说明
代码格式化
IDEA 代码格式化插件
1、安装 Eclipse Code Formatter**格式化插件**
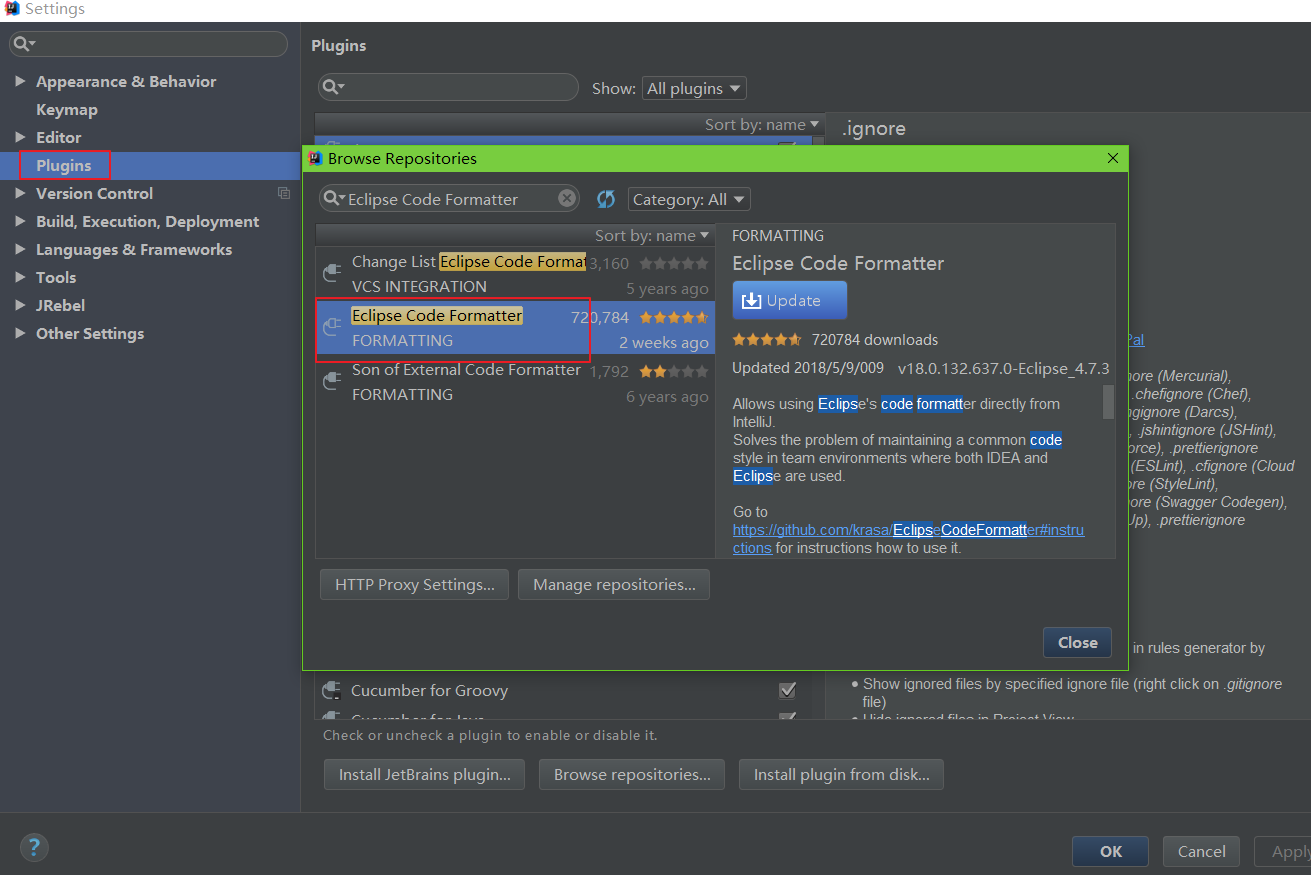
2、设置格式化配置文件
GoogleStyle:
eclipse-java-google-style.xml

3、使用快捷键**Ctrl+Alt+L**格式化代码

IDE 工具设置
IDEA 设置
1、修改import分组、排序规则
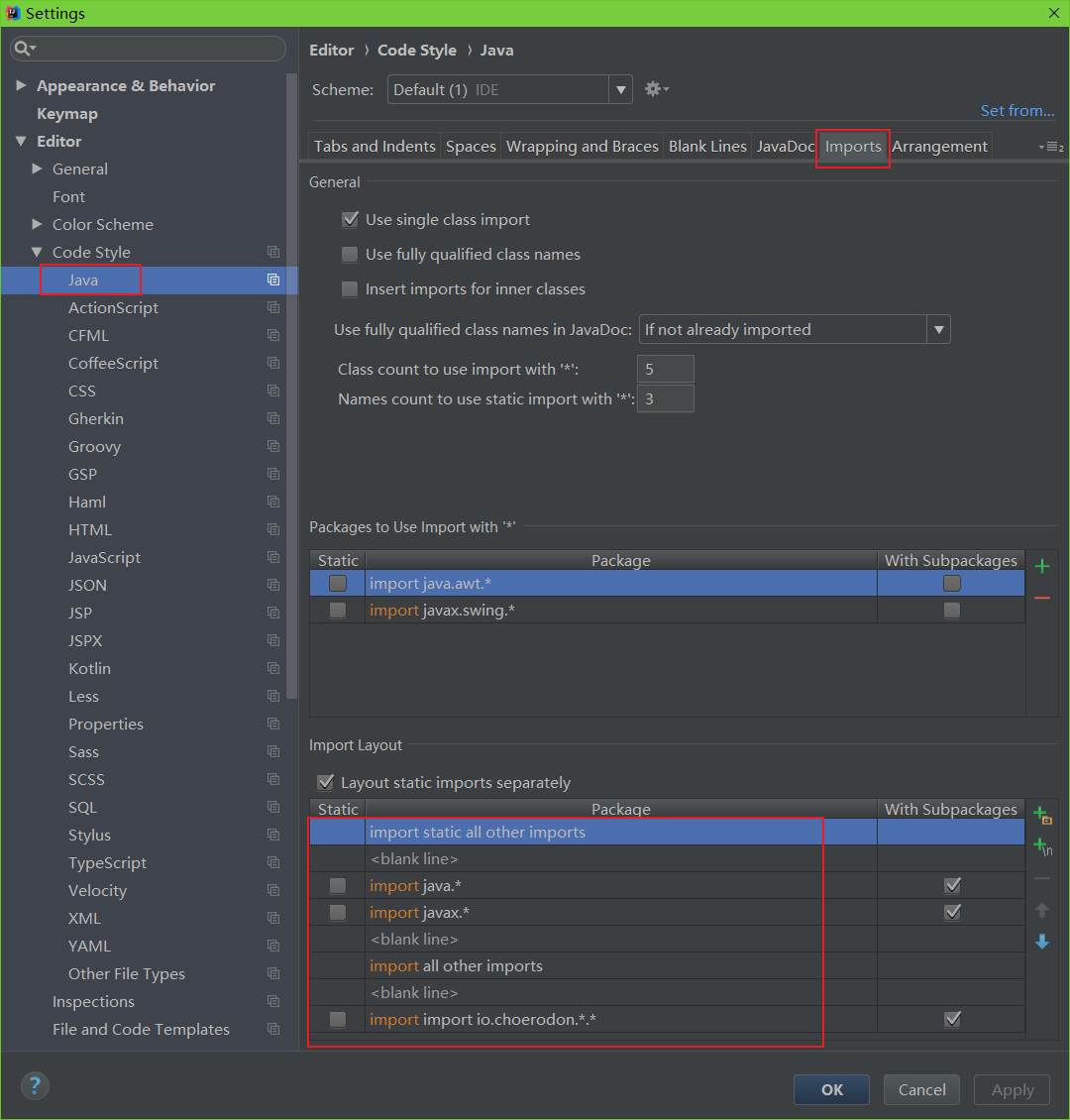
import static all other imports
<blank line>
import java.*
import javax.*
<blank line>
import all other imports
<blank line>
import io.choerodon.*
<blank line>
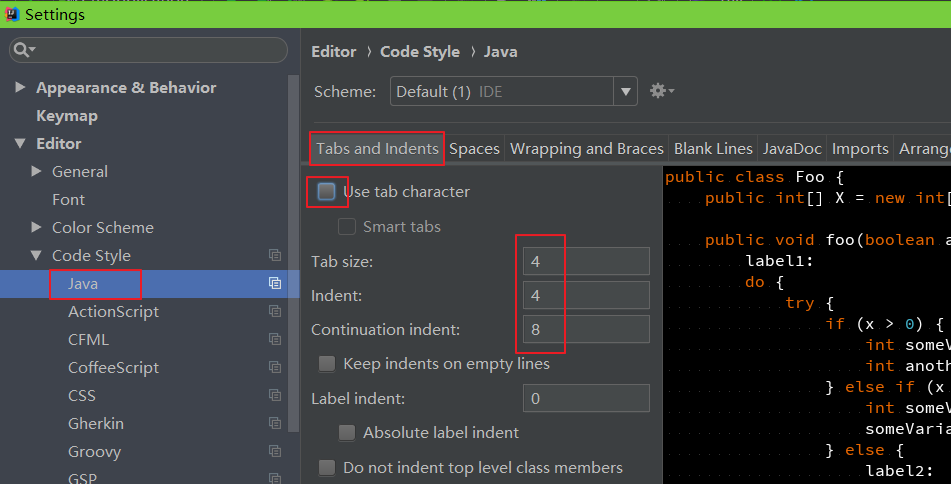
import org.hzero.*2、换行设置,统一120个字符换行
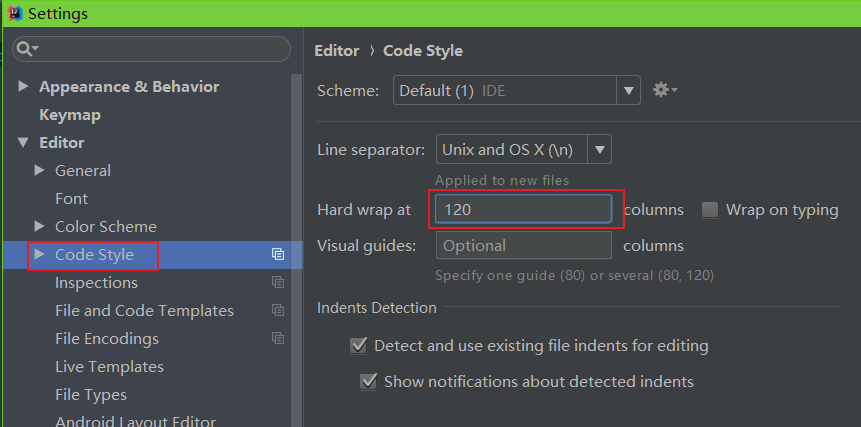
3、tab设置,统一使用**4**个空格为一个Tab
参考规范
- 总体规约以《阿里巴巴Java开发手册》为主,请开发人员至少阅读一遍该手册。
总体要求
- 代码提交之前使用 阿里巴巴规约**插件以及**SonarQube 插件扫描,可以开启阿里巴巴规约实时扫描。
- 保持代码整洁性,格式化代码。
- 代码命名规范,无论是包、类、方法、变量,见名知意。
- 多使用 jdk,自有库和被验证的第三方库的类和函数。
代码注释说明
良好的注释不仅可以帮助自己和其他开发者理解代码结构,也可以用在项目编译时生成javadoc,避免重复工作。
现代IDE可以通过模板的方式自动生成一些格式化的注释,在此我们提供模板的规范。请不要使用非Javadoc标准的注解,如@date。
类注释
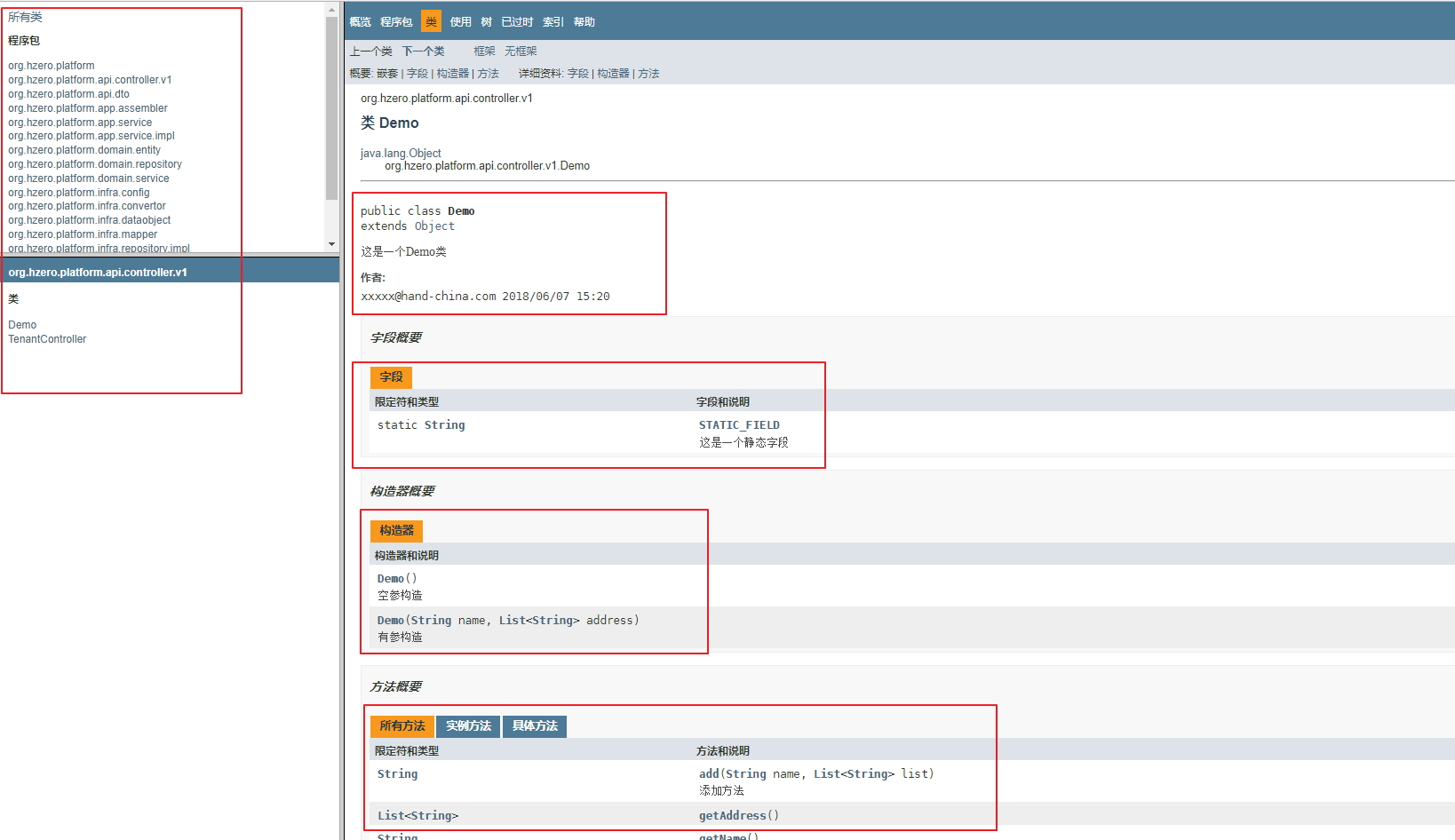
- 所有的类都必须使用 **Javadoc**,添加创建者和创建日期及描述信息,不得使用 // xxx 方式
/**
* <p>
* description
* </p>
*
* @author xxxx@hand-china.com 2018/06/07 13:48
*/
public class Demo {
}方法注释
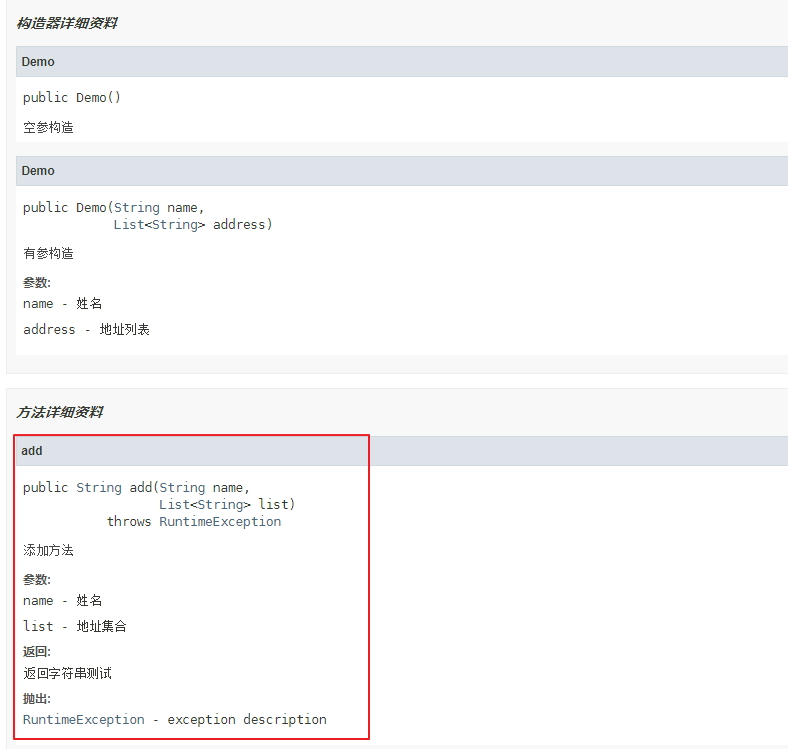
- 所有的抽象类、接口中的方法必须要用 **Javadoc 注释、除了返回值、参数、异常说明外,还必须指出该方法做什么事情,实现什么功能。对子类的实现要求,或者调用注意事项,请一并说明。**
/**
* <p>description<p/>
*
* @param name meaning
* @param list meaning
* @return the return
* @throws RuntimeException exception description
*/
String test(String name, List<String> list) throws RuntimeException;- 方法内部单行注释,在被注释语句上方另起一行,使用**//注释。方法内部多行注释使用/ /**注释,注意与代码对齐。
public void test(){
// 单行注释
String single = "";
/*
* 多行注释
* 多行注释
*/
String multi = "";
}- 私有方法可以使用 // xxx 注释,也可以使用Javadoc注释
// description
private void test3 () {
// ...
/* ... */
}字段注释
- 实体属性使用Javadoc注释,标明字段含义,这样getter/setter会含有注释。
- public 属性必须使用Javadoc注释
/**
* 静态字段描述
*/
public static final String STATIC_FIELD = "DEMO";
/**
* 姓名
*/
private String name;特殊注释标记
- 待办事宜(TODO):( 标记人,标记时间,[预计处理时间])表示需要实现,但目前还未实现的功能。
- 错误(FIXME):(标记人,标记时间,[预计处理时间])在注释中用 FIXME 标记某代码是错误的,而且不能工作,需要及时纠正的情况。
public void test3 () {
// TODO 待完成 [author, time]
// FIXME 待修复 [author, time]
}分隔符
- 有时需要划分区块,可以使用分隔符进行分隔
//
// 说明
// ------------------------------------------------------------------------------
//===============================================================================
// 说明
//===============================================================================其它
- 同一个类多个人开发,如有必要请在类、方法上加上负责人、时间信息
- 代码修改的同时,注释也要进行相应的修改,尤其是参数、返回值、异常、核心逻辑等的修改
- 对于注释的要求:第一、能够准确反应设计思想和代码逻辑;第二、能够描述业务含义,使别的程序员能够迅速了解到代码背后的信息。
- 好的命名、代码结构是自解释的,注释力求精简准确、表达到位。避免出现注释的一个极端:过多过滥的注释,代码的逻辑一旦修改,修改注释是相当大的负担。
IntelliJ IDEA 注释模板
IntelliJ IDEA 只能通过设置注释模板来实现,请先导入
IDEA注释模板。 File -> Import Settings
该模板内置了几种常用注释:
- 创建类时默认生成标准的Javadoc注释
- 使用 cc + Enter 生成类注释
- 使用 mc + Enter 生成方法注释,这个需要在方法内部生成,然后剪贴到方法上
- 使用** hc + Enter / dc + Enter **生成区块注释
JavaDoc
日志规范
异常类型
1.**debug
非常具体的信息,只能用于开发调试使用。部署到生产环境后,这个级别的信息只能保持很短的时间。这些信息只能临时存在,并将最终被关闭。要区分 DEBUG和TRACE会比较困难,对一个在开发及测试完成后将被删除的LOG输出,可能会比较适合定义为TRACE**级别.
2.**info
重要的业务处理已经结束。在实际环境中,系统管理员或者高级用户要能理解 INFO 输出的信息并能很快的了解应用正在做什么。比如,一个和处理机票预订的系统,对每一张票要有且只有一条 INFO信 息描述 “ [Who] booked ticket from [Where] to [Where] ”。另外一种对 INFO 信息的定义是:记录显著改变应用状态的每一个**action****,比如:数据库更新、外部系统请求。
3. warn
发生这个级别问题时,处理过程可以继续,但必须对这个问题给予额外关注。这个问题又可以细分成两种情况:
- 第一种是存在严重的问题但有应急措施(比如数据库不可用,使用Cache);
- 第二种是潜在问题及建议(ATTENTION)。
比如生产环境的应用运行在**Development模式下、管理控制台没有密码保护等。系统可以允许这种错误的存在,但必须及时做跟踪检查用户参数错误。可以使用warn**日志级别来记录用户输入参数错误的情况,避免用户投诉时,无所适从。
4. error
系统中发生了非常严重的问题,必须马上有人进行处理。没有系统可以忍受这个级别的问题的存在。比如:NPEs(空指针异常),数据库不可用,关键业务流程中断等等。
异常规范
1.返回给前端接口统一抛出**io.choerodon.core.exception.CommonException异常,这样返回给前端的状态码为200,前端通过failed是否为true**判断成功与否。
2.内部接口(用于被其他服务通过feign或ribbon调用的),统一抛出**io.choerodon.core.exception.FeignException异常,抛出异常时状态码为500,方便接口调用端“感知**”异常。
3.手动抛异常时应该把**exception**一块抛出,可以保留异常堆栈。
try {
String input = mapper.writeValueAsString(projectEventMsg);
sagaClient.startSaga(PROJECT_UPDATE, new StartInstanceDTO(input, “project”, “” + projectDO.getId()));
} catch (Exception e) {
throw new CommonException(“error.projectService.update.event”, e);
}4.不允许记录日志后又抛出异常,因为这样会多次记录日志,只允许记录一次日志,应尽量抛出异常,顶层打印一次日志。
5.使用SLF4J中的API进行日志打印, 在一个对象中通常只使用一个**Logger对象,Logger应该是static final**的。
private static final Logger LOGGER= LoggerFactory.getLogger(Abc.class)。
6.对**trace/debug/info**级别的日志输出,必须使用占位符的方式。
错误示例:logger.debug(“Processing trade with id: “ + id + “ symbol: “ + symbol);
如果日志级别是** warn,上述日志不会打印,但是会执行字符串拼接操作,如果symbol是对象,会执行 toString()方法,浪费了系统资源,执行了上述操作,最终日志却没有打印。所以应该使用:logger.debug(“Processing trade with id:{} and symbol : {} “, id, symbol); 另外如果日志输出的值是复杂操作,如JSON操作等,建议先判断是否输出日志,再进行处理:if (logger.isDebugEnabled()) { logger.debug(“Processing symbol:{}”, JSON.toJSONString(symbol));}**
7.输出的**POJO类必须重写toString方法,否则只输出此对象的hashCode**值(地址值),没啥参考意义。
8.输出**Exceptions的全部Throwable**信息。
- LOGGER.error(e.getMessage()); 错误,失掉StackTrace信息
- LOGGER.error(“Bad things : {}”,e.getMessage()); 错误,失掉StackTrace信息
- LOGGER.error(“Bad things : {}”,e); 正确
9.不允许出现**System print**(包括System.out.println和System.error.println)语句。
10.不允许出现**printStackTrace。堆栈打印应该LOGGER.error**(“Bad things : {}”,e)。
日志格式
1.将附件中的 logback-spring.xml 放入 src/main/resources/ 中,根据自己项目的实际情况进行调整,如果是容器部署,注意日志文件目录映射到共享存储中,便于后续分析和监控。
异常规范
在开发使用中,异常应该能够很好地帮助我们定位到问题的所在。如果使用一种错误的方式,则bug很难被找到。
异常的分类
JAVA中有三种一般类型的可抛类: 检查性异常(checked exceptions)、非检查性异常(unchecked Exceptions)** 和 **错误(errors)** 。**
1.**Checked exceptions:必须通过方法进行声明。这些异常都继承自Exception类。一个Checked exception**声明了一些预期可能发生的异常。
2.**Unchecked exceptions:不需要声明的异常。大多继承自RuntimeException。例如NullPointerException,ArrayOutOfBoundsException**。同时这样的异常不应该捕获,而应该打印出堆栈信息。
3.**Errors:大多是一些运行环境的问题,这些问题可能会导致系统无法运行。例如OutOfMemoryError,StackOverflowError**。
用户自定义异常
1.当应用程序出现问题时,直接抛出自定义异常。
throw new DaoObjectNotFoundException("Couldn't find dao with id " + id);2.将自定义异常中的原始异常包装并抛出。
catch (NoSuchMethodException e) {
throw new DaoObjectNotFoundException("Couldn't find dao with id " + id, e);
}错误的做法:
1.不要吞下**catch**的异常。
try {
System.out.println("Never do that!");
} catch (AnyException exception) {
// Do nothing
}- 这样的捕获毫无意义。我们应该使用一定的日志输出来定位到问题。
2.方法上应该抛出具体的异常。而不是**Exception**。
public void foo() throws Exception { //错误方式
}
public void foo() throws SQLException { //正确方式
}3.要捕获异常的子类,而不是直接捕获**Exception**。
catch (Exception e) { //错误方式
}4.永远不要捕获**Throwable**类。
5.不要只是抛出一个新的异常,而应该包含堆栈信息。
错误的做法:
try {
// Do the logic
} catch (BankAccountNotFoundException exception) {
throw new BusinessException();
// or
throw new BusinessException("Some information: " + e.getMessage());
}正确的做法:
try {
// Do the logic
} catch (BankAccountNotFoundException exception) {
throw new BusinessException(exception);
// or
throw new BusinessException("Some information: " ,exception);
}6.要么记录异常要么抛出异常,但不要一起执行。
catch (NoSuchMethodException e) {
//错误方式
LOGGER.error("Some information", e);
throw e;
}7.不要在**finally**中再抛出异常。
try {
someMethod(); //Throws exceptionOne
} finally {
cleanUp(); //如果finally还抛出异常,那么exceptionOne将永远丢失
}- 如果**someMethod 和 cleanUp 都抛出异常,那么程序只会把第二个异常抛出来,原来的第一个异常(正确的原因)将永远丢失。**
8.始终只捕获实际可处理的异常。
catch (NoSuchMethodException e) {
throw e; //避免这种情况,因为它没有任何帮助
}- 不要为了捕捉异常而捕捉,只有在想要处理异常时才捕捉异常。
9.不要使用 printStackTrace() 语句或类似的方法。
10.如果你不打算处理异常,请使用**finally块而不是catch**块。
11.应该尽快抛出(throw)异常,并尽可能晚地捕获(catch)它。你应该做两件事:分装你的异常在最外层进行捕获,并且处理异常。
12.在捕获异常之后,需要通过finally 进行收尾。在使用io或者数据库连接等,最终需要去关闭并释放它。
13.不要使用 if-else** **来控制异常的捕获。
14.一个异常只能包含在一个日志中。
// 错误
LOGGER.debug("Using cache sector A");
LOGGER.debug("Using retry sector B");
// 正确
LOGGER.debug("Using cache sector A, using retry sector B");15.将所有相关信息尽可能地传递给异常。有用且信息丰富的异常消息和堆栈跟踪也非常重要。
16.在 JavaDoc 中记录应用程序中的所有异常。应该用 javadoc 来记录为什么定义这样一个异常。
17.异常应该有具体的层次结构。如果异常没有层次的话,则很难管理系统中异常的依赖关系。
类似这样
class Exception {}
class BusinessException extends Exception {}
class AccountingException extends BusinessException {}
class BillingCodeNotFoundException extends AccountingException {}
class HumanResourcesException extends BusinessException {}
class EmployeeNotFoundException extends HumanResourcesException {}REST API规约
基本设计原则
API根URL
如果预期系统非常庞大,则建议尽量将API部署到独立专用子域名(例如:“api.”)下;如果确定API很简单,不会进一步扩展,则可以考虑放到应用根域名下面(例如,“/api/”)。
- 独立子域名
https://api.example.com/v1/ - 共享应用根域名:
https://example.org/api/v1/
URI末尾不要添加“/”
多一个斜杠,语义完全不同,究竟是目录,还是资源,还是不确定而多做一次301跳转?尽量保持URI结构简洁、语义清晰。
- 负面case: http://api.canvas.com/shapes/
- 正面case: http://api.canvas.com/shapes
禁止在URL中使用“_”
目的是提高可读性,“”可能被文本查看器中的下划线特效遮蔽。建议使用连字符“-”替代下划线“”,使用“-”提高URI的可读性。
- 负面case: http://api.example.com/blogs/my_first_post
- 正面case: http://api.example.com/blogs/my-first-post
禁止使用大写字母
RFC 3986中规定URI区分大小写,但别用大写字母来为难程序员了,既不美观,又麻烦,同样的原则:建议使用连字符“-”连接不同单词。
不要在URI中包含扩展名
应鼓励REST API客户端使用HTTP提供的格式选择机制Accept request header。
建议URI中的名称使用复数
为了保持URI格式简洁统一,资源在URI中应统一使用复数形式,如需访问资源的一个实例,可以通过资源ID定位(@PathVariable)。
如何处理关联关系?
- http://api.college.com/students/3248234/courses - 检索学生3248234所学习的所有课程
- http://api.college.com/students/3248234/courses/physics - 检索学生3248234的所学习的物理课程
建议URI设计时只包含名词,不包含动词
每个URI代表一种资源或者资源集合,因此,建议只包含名词,不包含动词。
那么,如何告诉服务器端我们需要进行什么样的操作?CRUD?
答案是由HTTP动词表示。
- GET (SELECT):从服务器取出资源(一项或多项)。
- POST (CREATE):在服务器新建一个资源。
- PUT (UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
- PATCH (UPDATE):在服务器更新资源(客户端提供改变的属性)。
- DELETE (DELETE):从服务器删除资源。
尽量减少对第三方开发人员的随意约束
非常重要的一点:让第三方开发人员自己指定排序过滤器、返回结果集的约束条件;但强烈建议服务器端设置默认单页数量,否则,如果无限制,很可能造成服务器资源及网络资源过度消耗,响应缓慢,网络丢包等异常情况;同时,需要在API文档中明确默认约束条件。
租户级URI设计时需要包含租户ID
存在版本段时,租户ID放在版本段后面,不存在则放在版本段位置。Controller 方法中需通过** @PathVariable **获取租户ID参数。另外平台级的API操作多租户,在参数中传递租户ID即可,不在URI中区分。
HTTP响应设计
当客户端通过 API 向服务器发起请求时,无论请求是成功、失败还是错误,客户端都应该获得反馈。HTTP 状态码是一堆标准化的数值码,在不同的情况下具有不同的解释。服务器应始终返回正确的状态码。
完整状态码参见:Status Code Definitions
2xx (成功类别)
这些状态代码表示请求的操作已被服务器接收到并成功处理。
- 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
- 201 CREATED - [POST/PUT/PATCH]:用户创建或修改实例成功时,应返回此状态代码。例如,使用 POST 方法创建一个新的实例,应该始终返回 201 状态码。
- 202 *Accepted - []:表示一个请求已经进入后台排队(异步任务)**
- 204 NO CONTENT - [DELETE]:内容不存在,表示请求已被成功处理,但并未返回任何内容。例如,DELETE算是其中一个很好的例子,用户删除数据成功。**API DELETE /companies/43/employees/2 将删除员工 2,作为响应,我们不需要在该 API 的响应正文中的任何数据,因为我们明确地要求系统将其删除。如果有任何错误发生,例如,如果员工 2 在数据库中不存在,那么响应码将不是 2xx 对应的成功类别,而是 4xx 客户端错误类别。**
3xx (重定向类别)
- 304 Not Modified - [GET]:未修改,表示客户端的响应已经在其缓存中。 因此,不需要再次传送相同的数据。
4xx (客户端错误类别)
这些状态代码表示客户端发起了错误的请求。
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
- 401 *Unauthorized - []:未授权:表示客户端不被允许访问该资源,需要使用指定凭证重新请求(令牌、用户名、密码等)。**
- 403 *Forbidden - []:禁止访问,表示请求是有效的并且客户端已通过身份验证(与401错误相对),但客户端不被允许以任何理由访问对应页面或资源。 例如,有时授权的客户端不被允许访问服务器上的目录。**
- 404 *NOT FOUND - []:未找到,表示所请求的资源现在不可用。例如,用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。**
- 410 Gone - [GET]: 资源不可用,表示所请求的资源后续不再可用,该资源已被永久移动。
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
5xx(服务器错误类别)
表示服务器端发生异常。
- 500 服务器内部错误,表示请求已经被接收到了,但服务器被要求处理某些未预设的请求而完全混乱。
- 503 服务不可用表示服务器已关闭或无法接收和处理请求。大多数情况是服务器正在进行维护。**
API版本管理
总体建议
- 建议通过URI指定服务版本,版本采用字符“v”+数字主版本号,例如,/v1/xxxs
- 建议版本控制在资源层面,也即Controller维度
- 服务后端分包建议规则如下:
- Domain:** **com.xxx.[user].domain.entity
- Api:
- com.xxx.api.[user].controller.v1
- com.xxx.api.[user].controller.v2
- API升级建议
- 尽量做兼容性设计,不要随便升级版本
- 升级可分步实施,达到最终整个资源整体升级的目的,不同版本相互独立,便于后续拆分独立部署、独立维护等(可能存在代码重复,尽可能抽象通用服务或方法)
- 先将资源的部分方法升级至高版本,并进行灰度发布,例如,/v1/users/check升级至 /v2/users/check,其他API版本维持v1不变
- 升级资源的所有方法至高版本,并发布公告,要求客户限期升级API
- 停止旧版本服务
URL中指定版本
1、URI上添加版本号:例如, https://api.example.org/v1/users
2、参数中添加版本号: 例如, https://api.example.org/users?v=1.0
好处:
- 直接可以在URI中直观的看到API版本;
- 可以直接在浏览器中查看各个版本API的结果;
坏处:
- 版本号在URI中破坏了REST的HATEOAS(hypermedia as the engine of application state)规则。版本号和资源之间并无直接关系。
Action 命名规范
| Description | Action Name | HTTP Mapping | HTTP Request Body | HTTP Response Body |
|---|---|---|---|---|
| 查询所有 | list | GET | N/A | *Resource list** |
| 获取单个资源 | query | GET | N/A | **Resource*** |
| 创建单个资源 | create | POST | Resource | **Resource*** |
| 更新单个资源 | update | PUT | Resource | **Resource*** |
| 删除单个资源 | delete | DELETE | N/A | Empty |
List
List 方法接受一个 **Collection id **和0或多个参数作为输入,并返回一个列表的资源。
- List 必须使用 GET 方法
- 接口必须以 collection id 结尾。
- 其他的请求字段必须作为 url 查询参数。
- 没有请求体,接口上必须不能包含request body。
- 响应体应该包含一组资源和一些可选项元数据。
- 没有资源可返回时,需返回一个空列表,禁止直接返回null。
- 响应HttpStatus 200。
Query
Query 方法接受一个 **Resource name 和0或多个参数,并返回指定的资源。
- Query** 必须使 GET 方法。
- 请求url 必须包含 Resource name。**
- 其他的请求字段必须作为 url 查询参数。
- 没有请求体,接口上必须不能包含request body。
- 响应体应该返回整个资源对象。
- 响应HttpStatus 200。
Create
Create 方法接受一个 Collection id **,一个资源,和0或多个参数。它创建一个新的资源在指定的父资源下,并返回新创建的资源。
- Create** 必须使用 POST 方法。
- 应该包含父资源名用于指定资源创建的位置。
- 创建的资源应该对应在request body。
- 响应体应该返回整个资源对象。
- Create 必须传递一个resource,这样即使resource 的结构发生变化,也不需要去更新方法或者资源结构,那些弃用的字段则需要标识为“只读”。
- 响应HttpStatus 201。
Update
Update 方法接受一个资源和0或多个参数。更新指定的资源和其属性,并返回更新的资源。
- 除了 Resource Name** **和其父资源之外,这个资源的所有属性应该是可以更新的。资源的重命名和移动则需要自定义方法。
- 如果只支持一个完整对象的更新 Update 必须使用 PUT 方法。
- Resource Name 必须包含在请求的url中。
- 资源应该对应在request body。
- 响应HttpStatus 200。
Delete
Delete** 方法接受一个Resource Name 和0或多个参数,并删除指定的资源。
- Delete 必须使用 DELETE 方法。
- Resource Name 必须包含在请求的url中。
- 没有请求体,接口上必须不能包含request body。
- 如果是立即删除,应该返回空
- 如果是启动一个删除操作,应该返回一个删除操作。
- 如果只是标识某个资源是“被删除的”,应该返回一个更新后的资源。
- 如果多个删除请求删除同一资源,那么只有第一个请求才应该成功,其他的返回not found。
- 响应HttpStatus 204。
自定义方法
自定义的方法应该参考5个基本方法。应该用于基本方法不能实现的功能性方法。可能需要一个任意请求并返回一个任意的响应,也可能是流媒体请求和响应。
可以对应a resource, a collection 甚至 a service。
- 自定义方法应该使用 POST 方法。不应该使用PATCH 方法。
- 自定义方法对应的 Resource Name 或者 Collection id **必须包含在请求的url中。
- 如果使用的HTTP 方法接受request body,则需要对应一个请求体。
- 如果使用的HTTP 方法不接受request body,则需要声明不使用body,并且参数应该作为url查询参数。
数据返回及异常规范
- 使用封装异常或错误消息,凡是可预见的异常或返回, **Response 的状态码始终是 200**。
- 前端通过判断** failed=true 来判断是否失败,请求成功则没有 failed 属性。因此不允许使用 failed **作为表字段或正常情况的返回字段。
- 后端必须对传入的数据做合法性校验,可以包装异常抛出,程序会自动捕获。
- 后端不需要返回细节的异常信息,如某个字段不为空。只需返回大范围上的异常信息,如 数据校验不通过 ,程序错误,请联系管理员 **。
- 前端应该对数据做好校验工作,按正常情况,视前端到后端的数据都是合法的。
Swagger描述规范
总体要求
通过Swagger进行管理的API说明对使用极为重要。
主要分三块:
- API目录描述(必须)
- API描述(必须)
- API参数描述(可选)
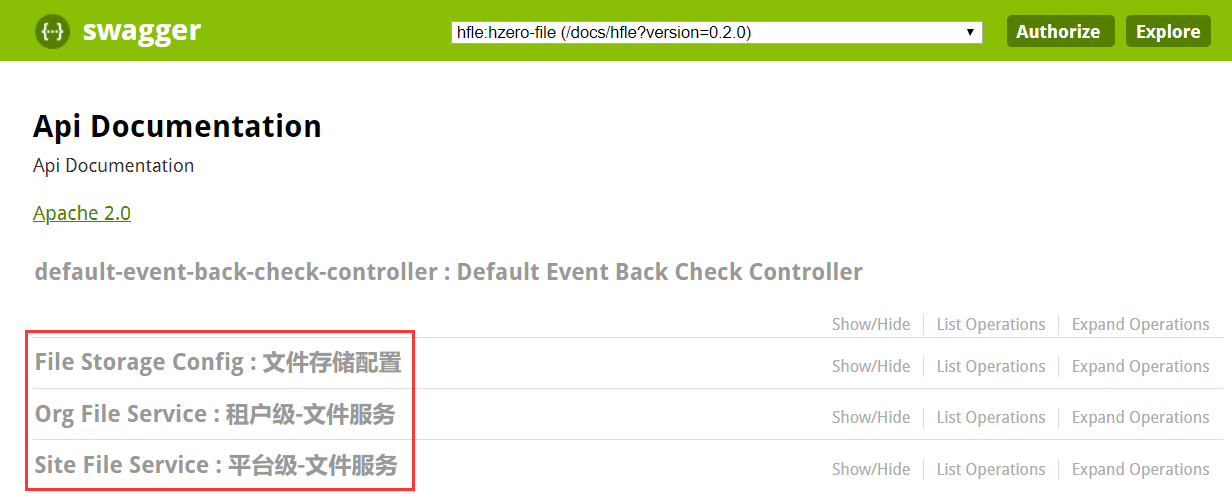
1.Swagger中API目录描述结构(英文描述:中文描述)
2.Swagger中API描述结构

3.Swagger中API参数描述结构
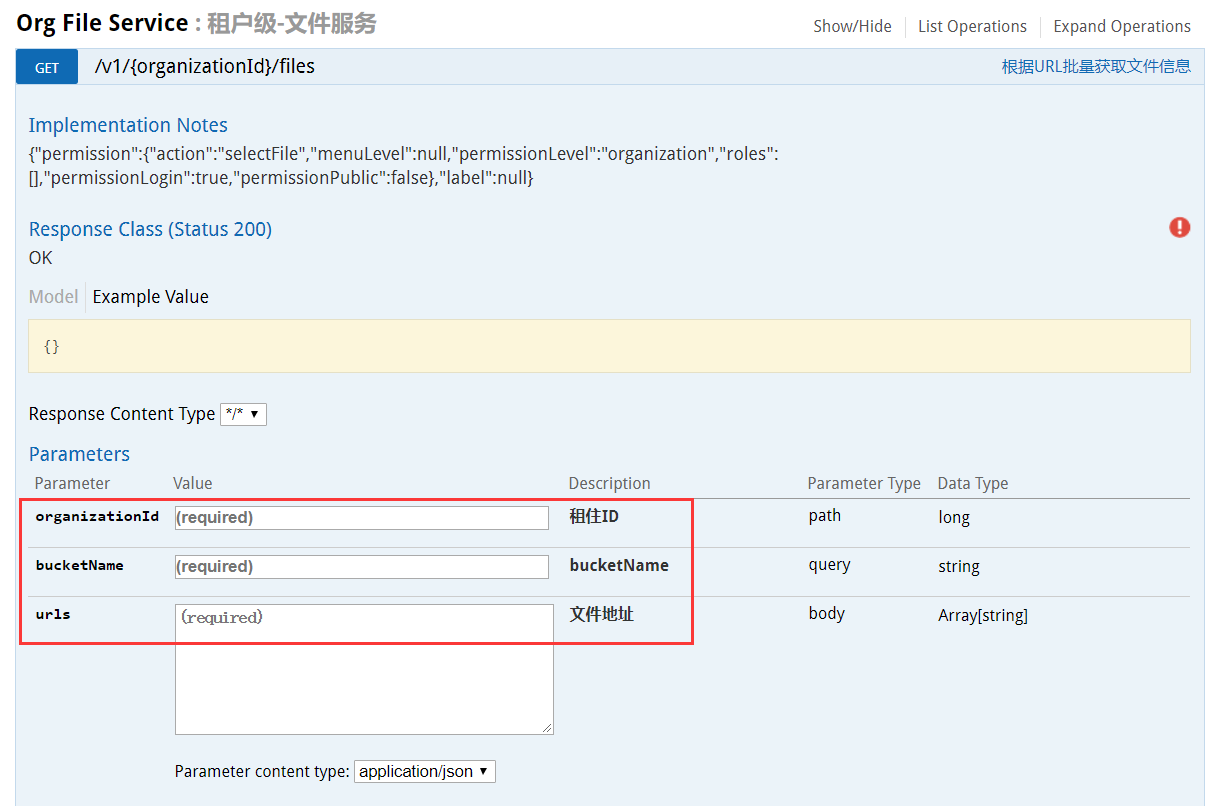
URL参数
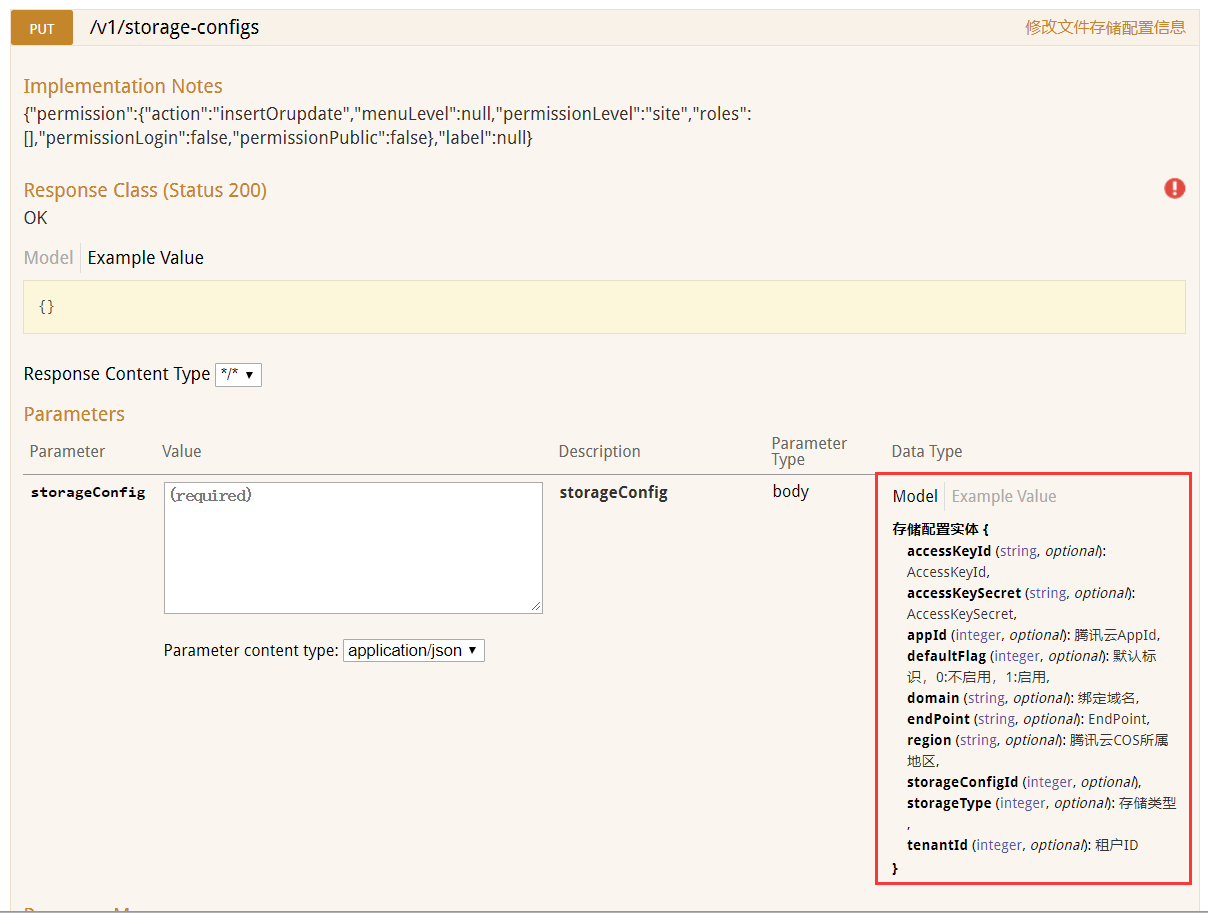
Body参数

此处评论已关闭