RDB与AOF的区别
- RDB属于全量同步 (定时同步)
优点:同步效率高
缺点:数据可能会丢失
- AOF属于增量同步有点偏向实时
优点:同步效率比较低,最多会丢失一秒钟的数据
平衡点:既然要效率高,数据不丢失肯定使用aof的everysec
如果aof与rdb都开优先使用aof
AOF
在Redis的配置文件中存在三种同步方式
appendfsync always每次有数据修改发生时都会写入AOF文件,能够保证数据不丢失,但是效率非常低。.
appendfsync everysec每秒钟同步一次,可能会丢失1s内的数据,但是效率非常高。
appendfsync no从不同步。高效但是数据不会被持久化。.
直接修改redis.conf 中 appendonly yes.
建议最好还是使用everysec 既能够保证数据的同步、效率也还可以。
RDB
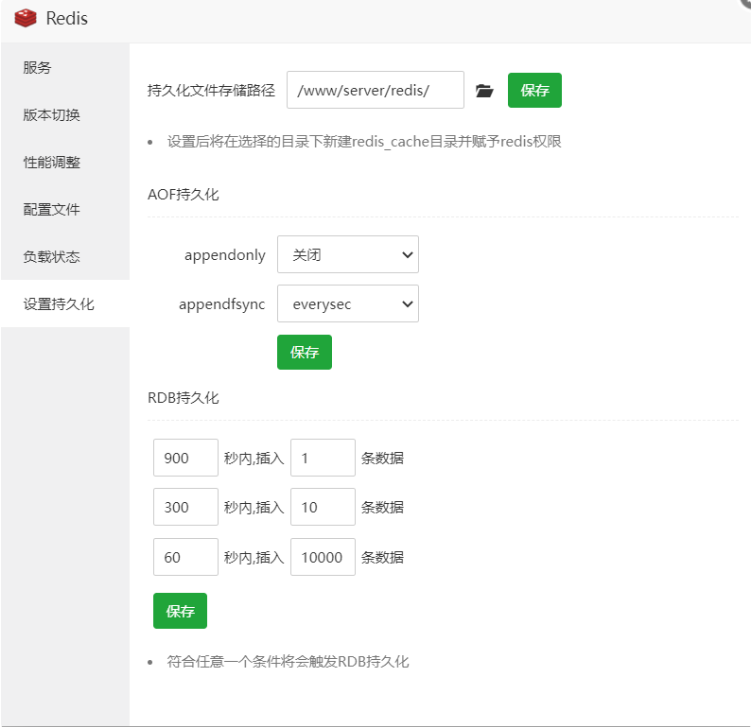
Redis默认采用rdb方式实现数据的持久化,以快照的形式将数据持久化到磁盘的是一个二进制的文件dump.rdb, 在redis.conf文件中搜索"dump.rdb"。
Redis会将数据集的快照dump到dump.rdb文件中。此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开 6379.conf文件之后,我们搜索save,可以看到下面的配置信息:
save 900 1在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
核心六大淘汰策略
Redis数据存放在内存里面有可能会防止内存撑爆有会淘汰策略。``
内存的淘汰策略:在Redis服务器上设置存放缓存的阈值(100mb 1g).
将 Redis用作缓存时,如果内存空间用满,就会自动驱逐老的数据。
- noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错。
- allkeys-lru:在主键空间中,优先移除最近未使用的key。(推荐)。
- volatile-Iru:在设置了过期时间的键空间中,优先移除最近未使用的 key。
- allkeys-random:在主键空间中,随机移除某个key。
- volatile-random:在设置了过期时间的链空间中,随机移除某个 key。
- volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。
如何配置Redis淘汰策略

在redis.conf 文件中 # maxmemory <bytes> 设置Redis内存大小的限制,我们可以设置当数据达到限定大小后,会选择配置的淘汰策略淘汰数据
比如:maxmemory 256MB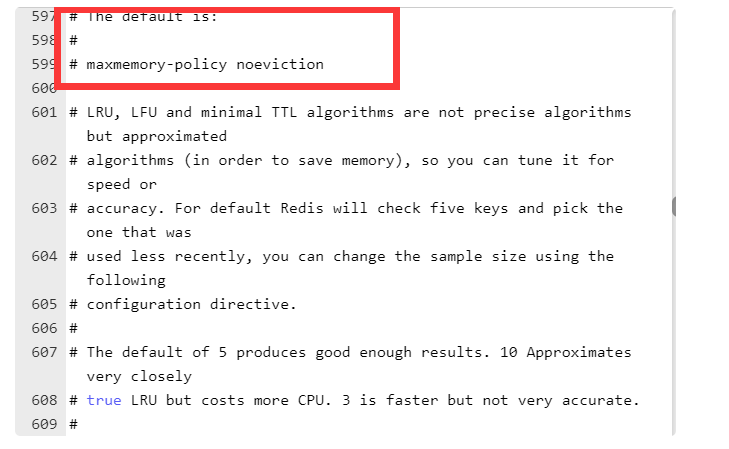
通过配置 maxmemory-policy noeviction 设置redis的淘汰策略。
比如:maxmemory-policy volatile-lru
Redis 中的自动过期机制
实现需求:处理订单过期白动取消,比如下单30分钟未支付自动更改订单状态
- 采用定时任务,30min后去检查该笔订单是否以及支付
- 根据key的有效期进行回调
原理:
- 创建订单的时候绑定一个token存放在redis(有效期只有30min)key=token value=订单id
- 对该key绑定过期事件的回调,执行我们的回调方法传递
使用Redis Key自动过期机制
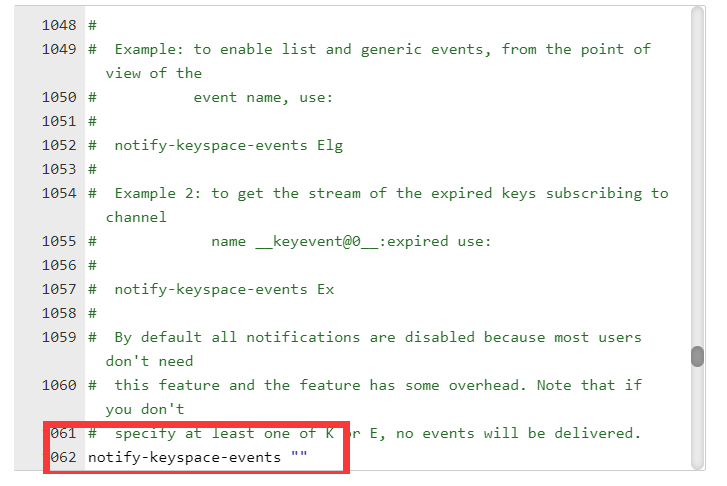
当我们的 key 失效时,可以执行我们的客户端回调监听的方法。
需要在 Redis_中配置: notify-keyspace-events "Ex"
SpringBoot整合key失效监听
@Configuration
public class RedisListenerConfig {
@Bean
RedisMessageListenerContainer container(RedisConnectionFactory connectionFactory) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
return container;
}
}@Component
public class RedisKeyExpirationListener extends KeyExpirationEventMessageListener {
public RedisKeyExpirationListener(RedisMessageListenerContainer listenerContainer) {
super(listenerContainer);
}
/**
* 待支付
*/
private static final Integer ORDER_STAYPAY = 0;
/**
* 失效
*/
private static final Integer ORDER_INVALID = 2;
@Autowired
private OrderMapper orderMapper;
/**
* Redis失效事件 key
*
* @param message
* @param pattern
*/
@Override
public void onMessage(Message message, byte[] pattern) {
String expiraKey = message.toString();
// 根据key查询 value 如果还还是为待支付状态 将订单改为已经超时~~
OrderEntity orderNumber = orderMapper.getOrderNumber(expiraKey);
System.out.println(expiraKey);
if (orderNumber == null) {
return;
}
if (orderNumber.getOrderStatus().equals(ORDER_STAYPAY)) {
// 将订单状态改为已经失效
orderMapper.updateOrderStatus(expiraKey, ORDER_INVALID);
}
}
}@RequestMapping("/saveOrder")
public String saveOrder() {
// 1.生成token
String orderToken = UUID.randomUUID().toString();
String orderId = System.currentTimeMillis() + "";
//2. 将该token存放到redis中
redisUtils.setString(orderToken, orderId, 5L);
OrderEntity orderEntity = new OrderEntity(null, "xxx", orderId, orderToken);
int result = orderMapper.insertOrder(orderEntity);
return result > 0 ? "success" : "fail";
}Redis事务操作
- Multi 开启事务
- EXEC提交事务
- Watch可以监听一个或者多个key,在提交事务之前是否有发生了变化如果发生边了变化就不会提交事务,没有发生变化才可以提交事务。
Discard 取消提交事务
注意: Redis_官方是没有提供回滚方法,值提供了取消事务。
取消事务和回滚事务有什么区别?
Mysql中开启了支付对行数据上锁
Commit数据可以提交.
回滚:对事务和行锁都会撤销
Redis没有回滚,单纯取消事务(不提交事务)不上锁。
基于Redis实现分布式锁
什么是分布式锁?
在传统单机部署的情况下,可以使用Java并发处理相关的API(如ReentrantLcok或synchronized)进行互斥控制。
但是在分布式系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机并发控制锁策略失效,为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁的由来。
如果我们服务器是集群的时候,定时任务可能会重复执行可以采用分布式锁解决。
当多个进程不在同一个系统中,就需要用分布式锁控制多个进程对资源的访问。
分布式锁的特点
首先,为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
1、互斥性:任意时刻,只能有一个客户端获取锁,不能同时有两个客户端获取到锁。
2、安全性:锁只能被持有该锁的客户端删除,不能由其它客户端删除。
3、死锁:获取锁的客户端因为某些原因(如down机等)而未能释放锁,其它客户端再也无法获取到该锁。
4、容错:当部分节点(redis节点等)down机时,客户端仍然能够获取锁和释放锁。
分布式锁的具体实现
分布式锁一般有三种实现方式:
- 数据库乐观锁;
- 基于ZooKeeper的分布式锁;
3.基于Redis的分布式锁;
解决分布式锁核心思路 - 获取锁
多个不同的jvm同时创建一个标记使用setnx命令,因为Rediskey必须保证是唯一的,只要谁 能够创建成功就能够获取锁
Set命令的时候:如果key不存在则创建,如果不存在则修改
SetNx 命令:如果不存在则创建 返回1(integer),如果已经存在则不执行任何操作返回 0
1:不存在创建成功 0:已经存在,不执行任何操作。
- 释放锁
对我们的Redis的key设置一个有效期(或者是主动的删除该key)可以灵活的自动的释放该全局唯一的标记,其他的jvm重新进入到获取锁资源。
- 超时锁(没有获取锁,已经获取锁)
等待获取锁的超时时间
已经获取到了锁,锁的有效期
分布式锁代码举例
public class RedisLock {
private static int lockSuccess = 1;
/**
* @param lockKey 在Redis中创建的key值
* @param notLockTimie 尝试获取锁超时时间
* @return 返回lock成功值
*/
public String getLock(String lockKey, int notLockTimie, int timeOut) {
//获取Redis连接
Jedis jedis = RedisUtil.getJedis();
// 计算我们尝试获取锁超时时间
Long endTime = System.currentTimeMillis() + notLockTimie;
// 当前系统时间小于endTime说明获取锁没有超时 继续循环 否则情况下推出循环
while (System.currentTimeMillis() < endTime) {
String lockValue = UUID.randomUUID().toString();
// 当多个不同的jvm同时创建一个相同的rediskey 只要谁能够创建成功谁就能够获取锁
if (jedis.setnx(lockKey, lockValue) == lockSuccess) {
// 加上有效期
jedis.expire(lockKey, timeOut / 1000);
return lockValue;
// 退出循环
}
// 否则情况下 继续循环
}
try {
if (jedis != null) {
jedis.close();
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
/**
* 释放锁
*
* @return
*/
public boolean unLock(String locKey, String lockValue) {
//获取Redis连接
Jedis jedis = RedisUtil.getJedis();
try {
// 判断获取锁的时候保证自己删除自己
if (lockValue.equals(jedis.get(locKey))) {
return jedis.del(locKey) > 0 ? true : false;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (jedis != null) {
jedis.close();
}
}
return false;
}
}测试分布式锁
private static final String LOCKKEY = "my_lock";
public static void service() {
// 1.获取锁
RedisLock RedisLock = new RedisLock();
String lockValue = RedisLock.getLock(LOCKKEY, 5000, 5000);
if (StringUtils.isEmpty(lockValue)) {
System.out.println(Thread.currentThread().getName() + ",获取锁失败了");
return;
}
// 执行我们的业务逻辑
System.out.println(Thread.currentThread().getName() + ",获取锁成功:lockValue:" + lockValue);
//
// // 3.释放锁
// RedisLock.unLock(LOCKKEY, lockValue);
}
public static void main(String[] args) {
service();
}尝试获取锁为什么次数限制?
如果我们业务逻辑5s 内没有执行完毕呢?
分场景:
1.锁的超时时间根据业务场景来预估
2.可以自己延迟锁的时间
3.在提交事务的时候检查锁是否已经超时 如果已经超时则回滚(手动回滚)否则提交。
仅限于单机版本
主从机制&哨兵集群
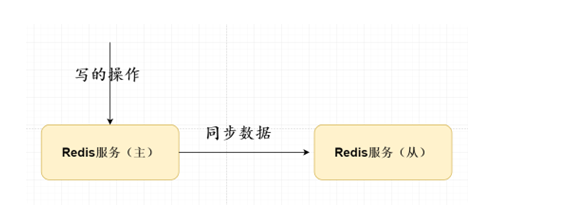
Redis主从复制
背景:单个Redis如果因为某种原因宣机的话,可能会导致整个Redis服务丕可用;可以使用Redis主从复制实现一主多从主节点负责写、从节点负责读数据。.
- 实现Redis集群
- 数据的备份
- 读写分离
主从复制需要注意问题:
主节点会将数据采用增量或者全量形式同步给从节点保证数据的一致性问题。
主从复制原理过程:
- 需要在从redis服务器配置在slaveof 执行 主redis服务ip地址和端口号
xx.xx.xx.xx:6379 (主的服务) 和密码; - 从Redis服务器和主Redis服务器建立Socket长连接;
- 采用全量和增量形式将数据同步给从Redis服务器
全量:从Redis首次启动的时候 (二进制执行dump 文件) rdb
增量:主Redis每次有新的set请求时候 aof 日志文件
传统的一主多同步效率比较 建议采用树状形式
主从复制还存在那些缺陷?
如果主的节点宕机之后,可能会导致整个Redis服务不能够实现写操作需要我们人为从新修改新的主的操作。基本概念:
单个Redis如果因为某种原因宕机的话,可能会导致Redis服务不可用,可以使用主从复制实现一主多从,主节点负责写的操作,从节点负责读的操作,主节点会定期将数据同步到从节点中,保证数据一致性的问题。
相关配置Redis.conf
#replicaof slaveof xxx.xxx.xxx.xxx 6379
masterauth 123456
info replication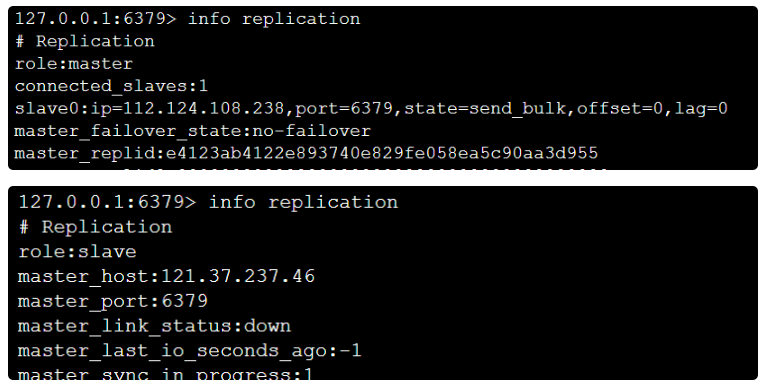
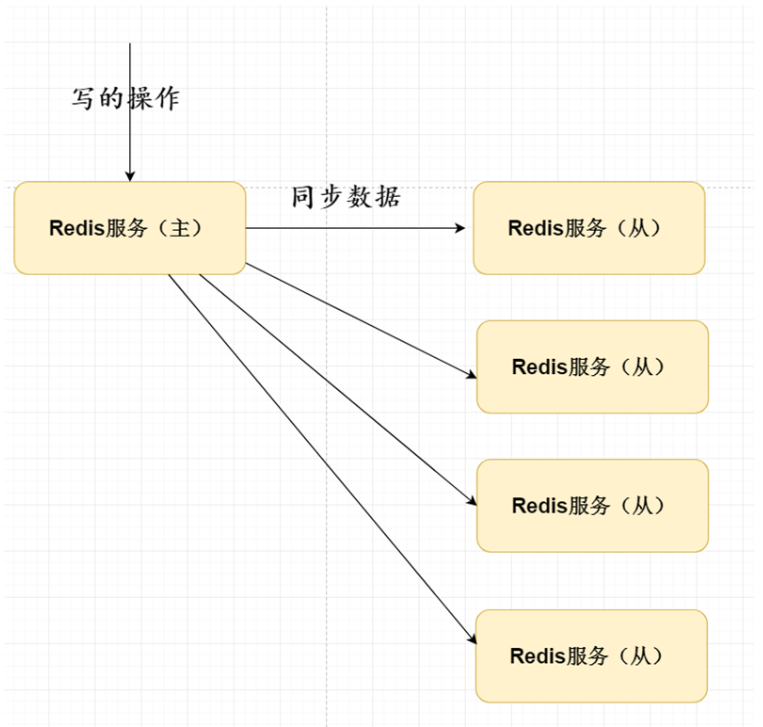
该主从同步方式存在 如果从节点非常多的话,会导致对主节点同步多个从节点压力非常大
可以采用树状类型解决该问题
主从复制数据同步的过程
- Redis从节点向主节点建立socket连接
- Redis采用全量或者增量的形式将数据同步给从节点
从Redis2.8版本以后 过程采用增量和全量同步
全量复制:一般用于在初次的复制场景(从节点与主节点一次建立)
增量复制:网络出现问题,从节点再次连接主节点时,主节点补发缺少的数据,每次数据增量同步
master:
slave:
主从复制存在那些缺陷
如果主节点存在了问题,整个Redis环境是不可以实现写的操作,需要人工更改配置变为主操作
如何解决该问题:使用哨兵机制可以帮助解决Redis集群主从选举策略。
Redis哨兵机制
Redis的哨兵机制就是解决我们以上主从复制存在缺陷(选举问题),解决问题保证我们的Redis高可用,实现自动化故障发现与故障转移。
哨兵机制原理
- 哨兵机制每个10s时间只需要配置监听我们的主节点就可以获取当前整个Redis集群的环境列表,采用info 命令形式。
- 哨兵不建议是单机的,最好每个Redis节点都需要配置哨兵监听。
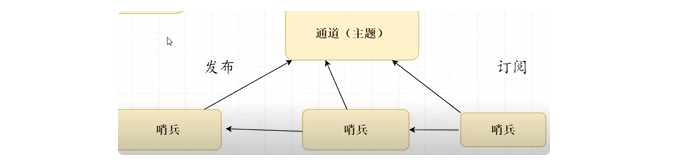
- 哨兵集群原理是如何:多个哨兵都执行同一个主的master节点,订阅到相同都通道,有新的哨兵加入都会向通道中发送自己服务的信息,该通道的订阅者可以发现新哨兵的加入,随后相互建立长连接。(类似于mq)
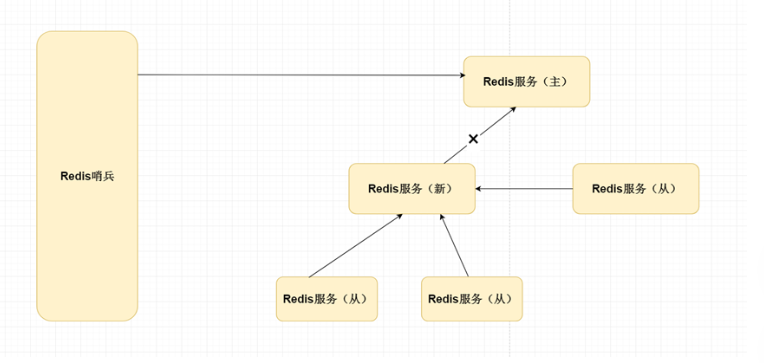
- Master的故障发现 单个哨兵会向主的master节点发送ping的命令,如果master节点没有及时的响应,哨兵会认为该master节点为“主观不可用状态”会发送给其他都哨兵确认该Master节点是否不可用,当前确认的哨兵节点数>=quorum(可配置),会实现重新选举。
相关核心配置
vi sentinel.conf
sentinel monitor mymaster 192.168.xx.xx 6379 2
sentinel auth-pass mymaster 123456设置后台启动
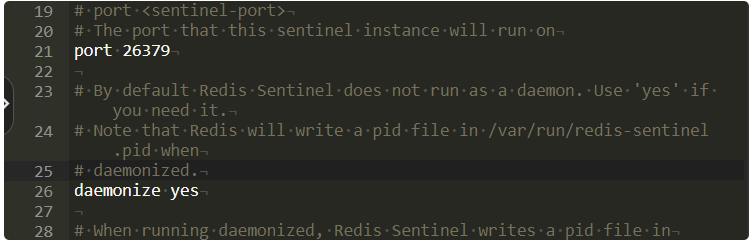
修改配置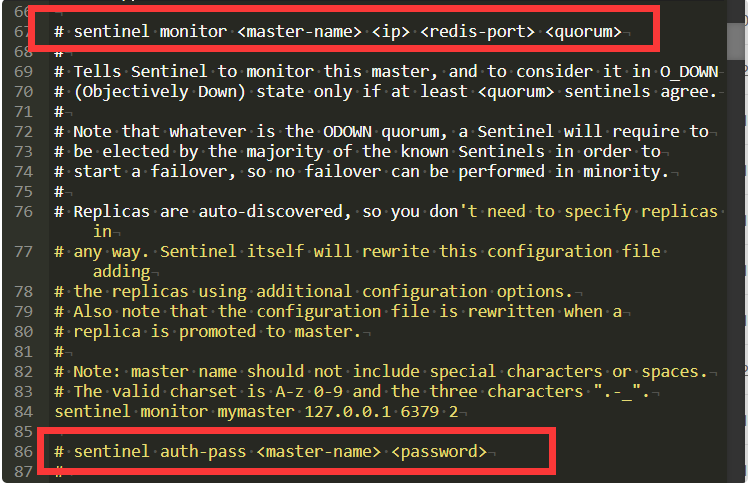
Master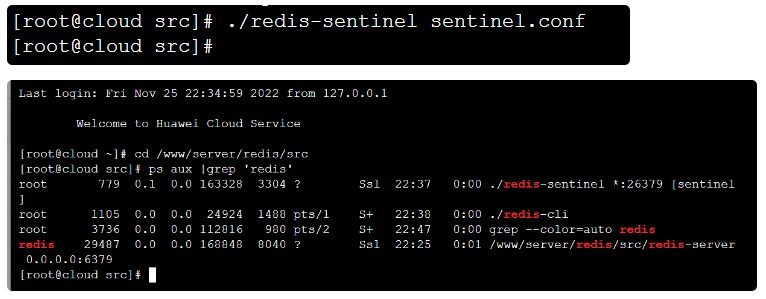
设置两个slave
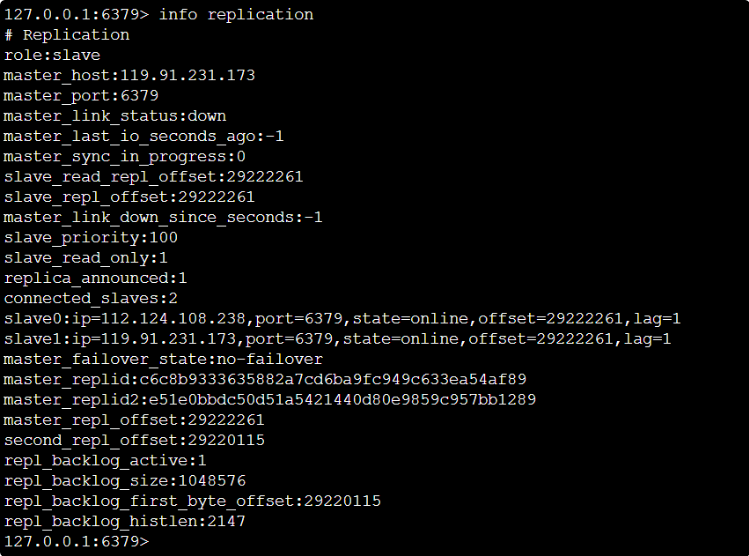
Slave

1号slave

停止master服务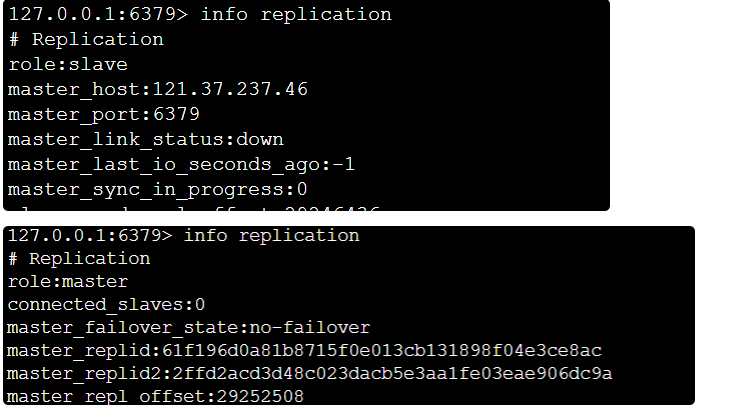
完成了主备切换
sentinel down-after-milliseconds mymaster 3000
sentinel心跳检测主3秒内无响应,视为挂掉,开始切换其他从为主
sentinel parallel-syncs mymaster 1
每次最多可以有1个从同步主。一个从同步结束,另一个从开始同步。
sentinel failover-timeout mymaster 18000
主从切换超时时间
注意:
- 在分布式领域不可能实现绝对强一致性 毕竟是有网络原因
Redis的主从复制作用:
单个Redis如果因为某种原因宕机的话,可能会导致整个Redis服务不可用;
可以使用Redis主从复制实现一主多从 主节点负责写、从节点负责读数据。
主节点会将数据采用增量或者全量形式同步给从节点保证数据的一致性问题。
缓存相关概念及解决方案
缓存穿透
缓存穿透理解
缓存穿透是指查询一个根本不存在的数据,缓存层和持久层都不会命中。在日常工作中出于容错的考虑,如果从持久层查不到数据则不写入缓存层,缓存穿透将导致不存在的数据每次请求都要到持久层去查询,失去了缓存保护后端持久的意义。
缓存穿透示意图: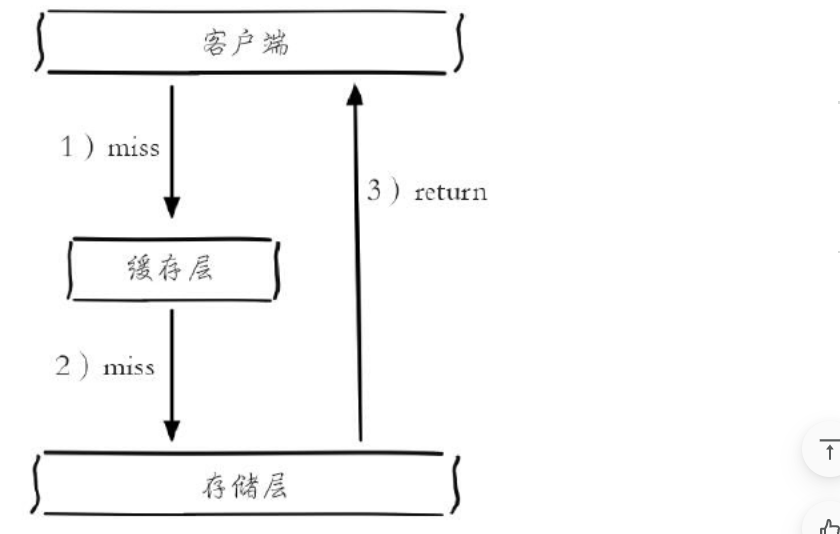
缓存穿透问题可能会使后端存储负载加大,由于很多后端持久层不具备高并发性,甚至可能造成后端存储宕机。通常可以在程序中统计总调用数、缓存层命中数、如果同一个Key的缓存命中率很低,可能就是出现了缓存穿透问题。
造成缓存穿透的基本原因有两个。第一,自身业务代码或者数据出现问题(例如:set 和 get 的key不一致),第二,一些恶意攻击、爬虫等造成大量空命中(爬取线上商城商品数据,超大循环递增商品的ID)
解决方案
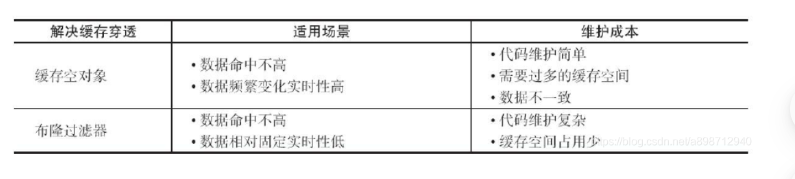
- 缓存空对象
缓存空对象:是指在持久层没有命中的情况下,对key进行set (key,null)
缓存空对象会有两个问题:
- value为null 不代表不占用内存空间,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间,比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
- 缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
- 布隆过滤器拦截
在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截,当收到一个对key请求时先用布隆过滤器验证是key否存在,如果存在在进入缓存层、存储层。可以使用bitmap做布隆过滤器。这种方法适用于数据命中不高、数据相对固定、实时性低的应用场景,代码维护较为复杂,但是缓存空间占用少。
布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器拦截的算法描述:
初始状态时,BloomFilter是一个长度为m的位数组,每一位都置为0。
添加元素x时,x使用k个hash函数得到k个hash值,对m取余,对应的bit位设置为1。
判断y是否属于这个集合,对y使用k个哈希函数得到k个哈希值,对m取余,所有对应的位置都是1,则认为y属于该集合(哈希冲突,可能存在误判),否则就认为y不属于该集合。可以通过增加哈希函数和增加二进制位数组的长度来降低错报率。
- 两种方案的对比
缓存击穿
缓存击穿的理解
系统中存在以下两个问题时需要引起注意:
当前key是一个热点key(例如一个秒杀活动),并发量非常大。
重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
- 对我们的服务接口api实现限流、用户授权、黑名单和白名单拦截;。
- 从缓存和数据库都查询不到结果的话,一样将数据库空值结果缓存到Redis,中。设置30s 的有效期避免使用同一个id对数据库攻击。
- 布隆过滤器
解决方案
- 分布式互斥锁
只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可。set(key,value,timeout)
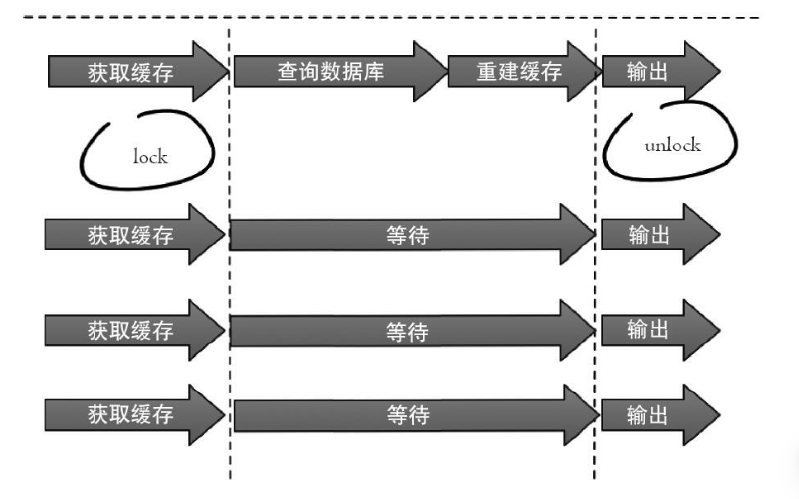
- 永不过期
从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。
从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去更新缓
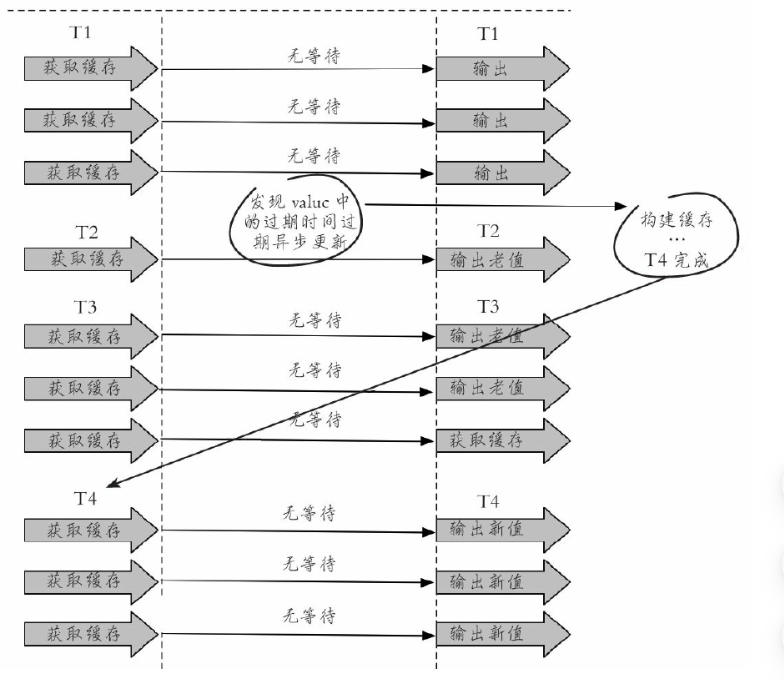
- 两种方案对比
分布式互斥锁:这种方案思路比较简单,但是存在一定的隐患,如果在查询数据库 + 和 重建缓存(key失效后进行了大量的计算)时间过长,也可能会存在死锁和线程池阻塞的风险,高并发情景下吞吐量会大大降低!但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好。
永远不过期:这种方案由于没有设置真正的过期时间,实际上已经不存在热点key产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。
缓存雪崩
概念理解
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
解决方案
- 缓存层高可用
可以把缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务。利用sentinel或cluster实现。 - 做二级缓存,或者双缓存策略:
采用多级缓存,本地进程作为一级缓存,redis作为二级缓存,不同级别的缓存设置的超时时间不同,即使某级缓存过期了,也有其他级别缓存兜底 - 数据预热
可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀 - 加锁排队. 限流-- 限流算法. 1.计数 2.滑动窗口 3. 令牌桶Token Bucket 4.漏桶 leaky bucket
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
布隆过滤器
在hashmap中get方法,时间复杂度O(1 )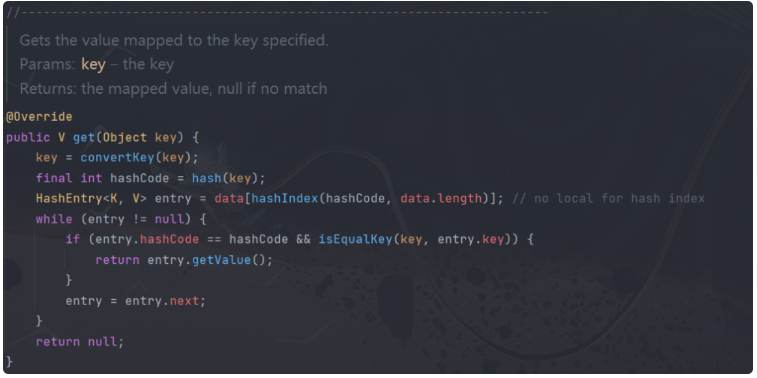
首先会去判断key是否为空
然后进行hash运算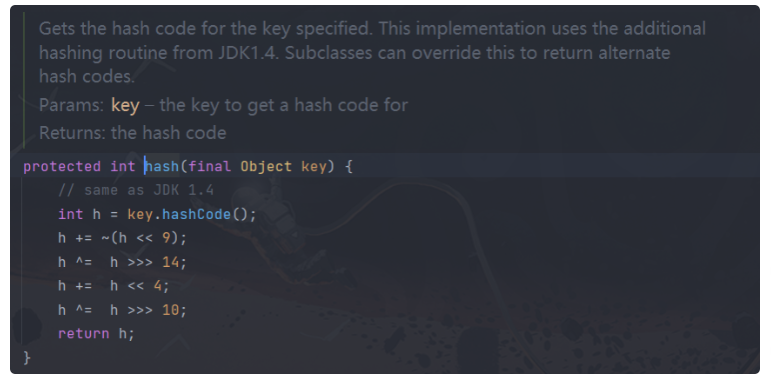
布隆过滤器适用于判断一个元素在集合中是否存在,但是可能会存在误判的问题。
/**
* 假设集合中存放1000万条数据
*/
private static Integer size = 10000000;
public static void main(String[] args) {
for(int z=0;z<5;z++) {
BloomFilter integerBloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
for (int i = 0; i < size; i++) {
// 向我们布隆过滤器中存放100万条数据
integerBloomFilter.put(i);
}
ArrayList integers = new ArrayList<>();
for (int j = size; j < size + 10000; j++) {
// 使用该pai判断key在布隆过滤器中是否存在 返回true 存在 false 表示不存在
if (integerBloomFilter.mightContain(j)) {
// 将布隆过滤器误判的结果存放到集合中方便后期统计
integers.add(j);
}
}
System.out.println("布隆过滤器误判的结果:" + integers.size());
// 0.03概率 数组长度730万左右 0.01
// 0.01概率 数组长度960万左右
}
}
}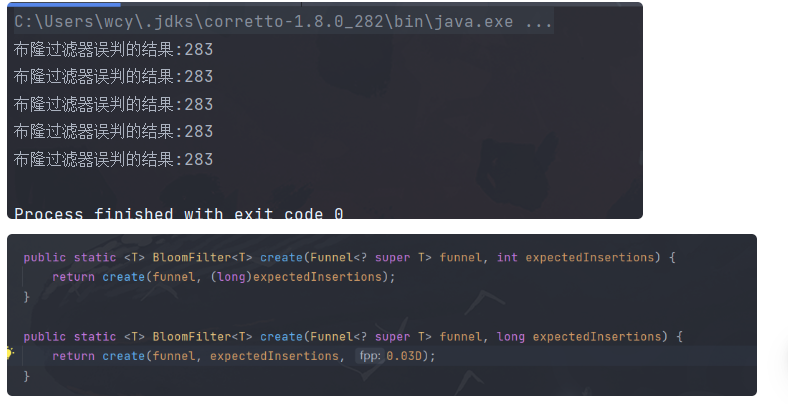
默认0.03表示误判的概率在3%
BloomFilter integerBloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.0000000001);我们·可以通过修改fpp的概率来减少误判的个数,但随之numBits数组长度会变得更长,但该数组存储的都是0和1相比于传统的map或者list占用内存空间会相对小很多
实现原理
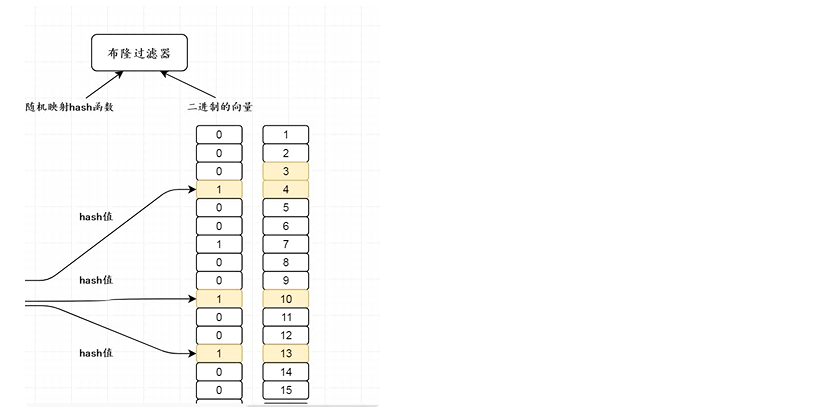
如何解决问题
二进制数组长度设置比较大,可以减少布隆误判的概率。
Java整合
<!--引入布隆过滤器 -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>@RequestMapping("/getOrder")
public OrderEntity getOrder(Integer orderId) {
// 0.判断我们的布隆过滤器
if (!integerBloomFilter.mightContain(orderId)) {
System.out.println("从布隆过滤器中查询不存在");
return null;
}
// 1.先查询Redis中数据是否存在
OrderEntity orderRedisEntity = (OrderEntity) redisTemplateUtils.getObject(orderId + "");
if (orderRedisEntity != null) {
System.out.println("直接从Redis中返回数据");
return orderRedisEntity;
}
// 2. 查询数据库的内容
System.out.println("从DB查询数据");
OrderEntity orderDBEntity = orderMapper.getOrderById(orderId);
if (orderDBEntity != null) {
System.out.println("将Db数据放入到Redis中");
redisTemplateUtils.setObject(orderId + "", orderDBEntity);
}
return orderDBEntity;
}
@RequestMapping("/dbToBulong")
public String dbToBulong() {
// 1.从数据库预热id到布隆过滤器中
List<Integer> orderIds = orderMapper.getOrderIds();
integerBloomFilter = BloomFilter.create(Funnels.integerFunnel(), orderIds.size(), 0.01);
for (int i = 0; i < orderIds.size(); i++) {
// 添加到我们的布隆过滤器中
integerBloomFilter.put(orderIds.get(i));
}
return "success";
}
此处评论已关闭