执行顺序
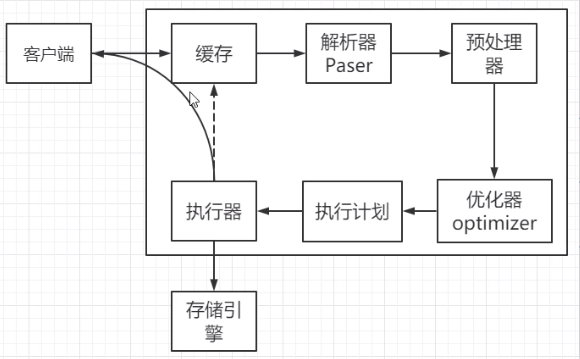
连接-配置优化
第一个环节是客户端连接到服务端,连接这一块有可能会出现什么样的性能问题?有可能是服务端连接数不够导致应用程序获取不到连接。比如报了一个
Mysql: error 1040: Too many connections可以从两个方面来解决连接数不够的问题:
1、从服务端来说,我们可以增加服务端的可用连接数。
如果有多个应用或者很多请求同时访问数据库,连接数不够的时候,我们可以:
(1)修改配置参数增加可用连接数,修改max_connections的大小:
show variables like 'max_connections'; --修改最大连接数,当有多个应用连接的时候(2)或者,或者及时释放不活动的连接。交互式和非交互式的客户端的默认超时时间都是28800秒,8小时,我们可以把这个值调小。
show global variables like 'wait_timeout"':--及时释放不活动的连接,注意不要释放连接池还在使用的连接2、从客户端来说,可以减少从服务端获取的连接数,如果我们想要不是每一次执行SQL都创建一个新的连接,可以引入连接池,实现连接的重用。
缓存-架构优化
缓存
在应用系统的并发数非常大的情况下,如果没有缓存,会造成两个问题:一方面是会给数据库带来很大的压力。另一方面,从应用的层面来说,操作数据的速度也会受到影响。
我们可以用第三方的缓存服务来解决这个问题,例如Redis。
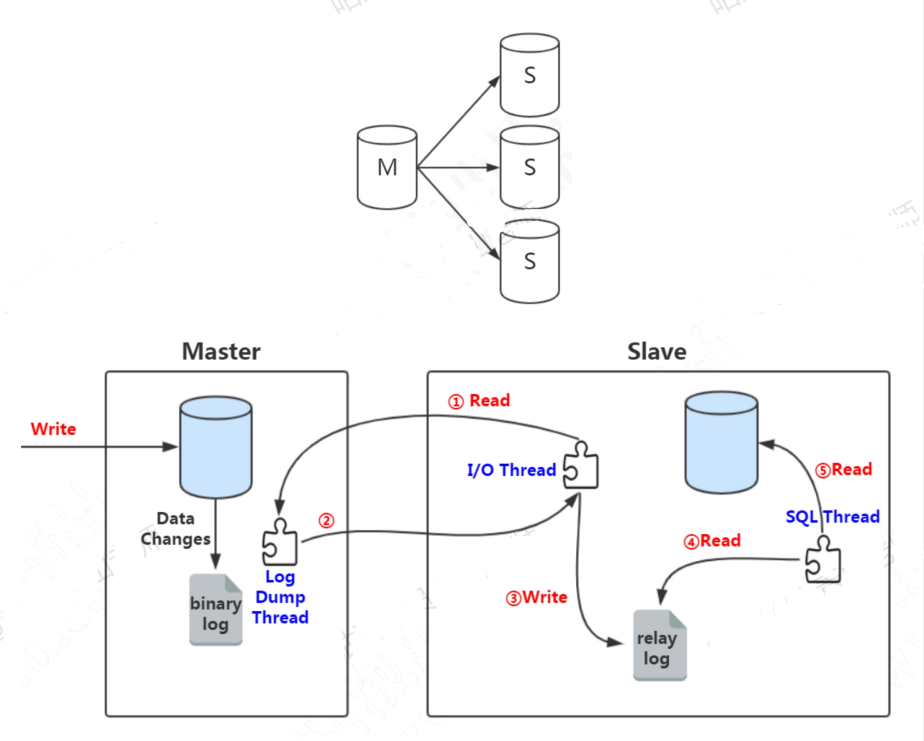
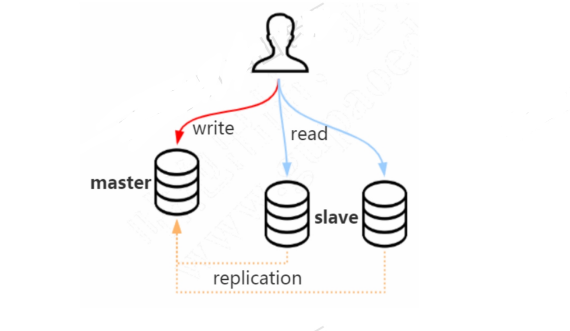
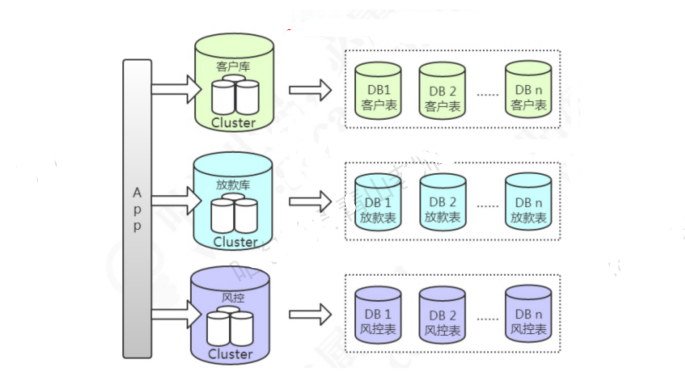
集群 主从复制如果单台数据库服务满足不了访问需求,那我没可以做数据库的集群方案。
做了主从复制的方案之后,我们只把数据写入master节点,而读的请求可以分担到slave节点。我们把这种方案叫做读写分离。
读写分离可以一定程度低减轻数据库服务器的访问压力,但是需要特别注意主从数据一致性的问题。

分库分表
垂直分库,减少并发压力。水平分表,解决存储瓶颈。
垂直分库的做法,把一个数据库
根据业务
拆分成不同的数据库:单库
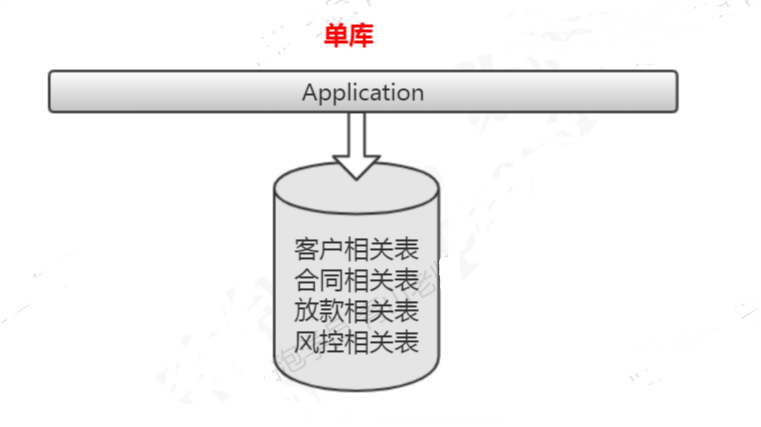
垂直分库

水平分库
水平分库分表的做法,把单张表的数据按照一定的规则分布到多个数据库。
优化器-sql语句分析与优化
我们的服务层每天执行了这么多SQL语句,它怎么知道哪些SQL语句比较慢呢?第一步,我们要把SQL执行情况记录下来。
慢查询日志slow query log
https://dev.mysql.com/doc/refman/5.7/en/slow-query-log.html
- 打开慢日志开关
因为开启慢查询日志是有代价的(跟bin log.optimizer-trace一样),所以它默认是关闭的:
show variables like 'slow_query%';除了这个开关,还有一个参数,控制执行超过多长时间的SQL才记录到慢日志,默认是10秒。如果改成0秒的话就是记录所有的SQL。
show variables like '%long_query%';可以直接动态修改参数(重启后失效)。
set a@global.slow_query_log=l;--1开启,О关闭,重启后失效
set a@global.long_query_time=3;--mysql默认的慢查询时间是10秒,另开一个窗口后才会查到最新值
show variables like "%long_query%';
show variables like '%oslow_query%';或者修改配置文件 my.cnf。
以下配置定义了慢查询日志的开关、慢查询的时间、日志文件的存放路径。
slow_query_log = ON
long_query_time=2
slow_query_log_file =/var/lib/mysqI/localhost-slow.log模拟慢查询:
select sleep(10);查询user_innodb表的500万数据(没有索引)。
SELECT* FROM 'user_innodb` where phone = '136';- 慢日志分析
日志内容
show global status like 'slow_queries'; --查看有多少慢查询
show variables like 1%slow_query%'; --获取慢日志目录mysqldumpslow
https://dev.mysql.com/doc/refman/5.7/en/mysqldumpslow.html
MySQL提供了mysqldumpslow 的工具,在MySQL的 bin目录下。
mysqldumpslow --help例如:查询用时最多的10条慢SQL:
mysqldumpslow -s t -t 10 -g 'select'/var/lib/mysqI/localhost-slow.logshow profile
https://dev.mysql.com/doc/refman/5.7/en/show-profile.html
SHOW PROFILE是谷歌高级架构师Jeremy Cole贡献给MySQL社区的,可以查看SQL语句执行的时候使用的资源,比如CPU、IO的消耗情况。
在SQL中输入 help profile可以得到详细的帮助信息。
-
查看是否开启
select @@profiling;
set @@profiling=l; -
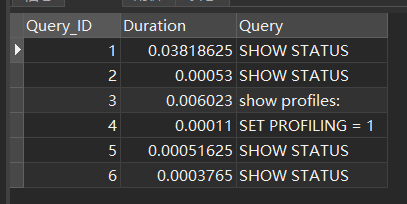
查看profile 统计
(命令最后带一个s)show profiles
查看最后一个SQL的执行详细信息,从中找出耗时较多的环节(没有s)。
show profile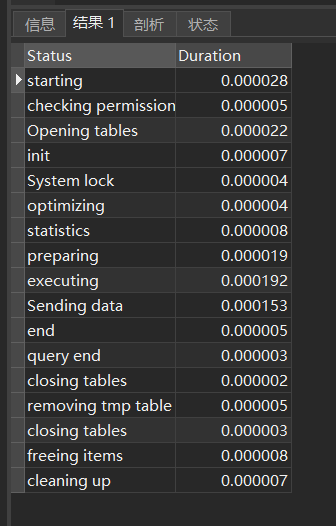
其他系统命令
分析Server层的运行信息,可以用show status。
show status 服务器运行状态
说明: https://dev.mysql.com/doc/refman/5.7/en/show-status.html
详细参数:https://dev.mysql.com/doc/refman/5.7/en/server-status-variables.html
SHOW STATUS用于查看MySQL服务器运行状态(重启后会清空)。
SHOW GLOBAL STATUS ;可以用like带通配符过滤,例如查看select语句的执行次数。
SHOW GLOBAL STATUS LIKE 'com_select'; --查看select次数show processlist运行线程
如果要分析服务层的连接信息,可以用
show processlistSQL与索引优化
Full Table Scan,如果没有索引或者没有用到索引,type就是ALL。代表全表扫描。
小结:
一般来说,需要保证查询至少达到range级别,最好能达到ref。ALL(全表扫描)和index(查询全部索引)都是需要优化的。
- possible_key、key
可能用到的索引和实际用到的索引。如果是NULL就代表没有用到索引。
possible_key可以有一个或者多个,比如查询多个字段上都有索引,或者一个字段同时有单列索引和联合索引。能用到的索引并不是越多越好。可能用到索引不代表一定用到索引。如果通过分析发现没有用到索引,就要检查SQL或者创建索引。
- key_len
索引的长度(使用的字节数)。跟索引字段的类型、长度有关。表上有联合索引: KEY comidx_name_phone ( name `, phone')
explain select * from user_innodb where name ='root';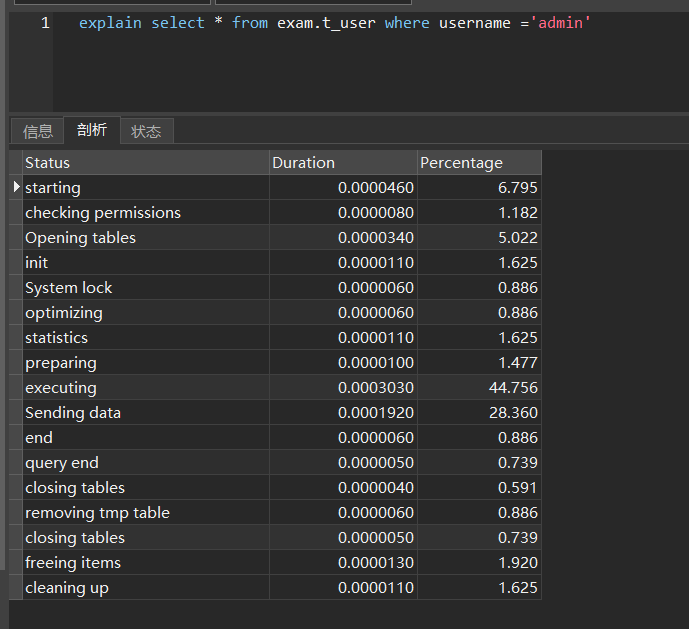
- rows
MySQL认为扫描多少行(数据或者索引)才能返回请求的数据,是一个预估值。一般来说行数越少越好。 - filtered
这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数
量的比例,它是一个百分比。如果比例很低,说明存储引擎层返回的数据需要经过大量过滤,这个是会消耗性能的,需要关注。
- ref
使用哪个列或者常数和索引一起从表中筛选数据,可以参考一下。
- Extra
执行计划给出的额外的信息说明。
在查询的时候,需要做去重、排序之类的工作的时候,可能会用到临时表。举几个例子:
-
distinct非索引列
EXPLAIN select DISTINCT(tid) from teacher t;
-
group by非索引列
EXPLAIN select tname from teacher group by tname;
-
使用join 的时候,group任意列
EXPLAIN select t.tid from teacher t join course c on t.tid = c.tid group by t.tid;
Using Temporary 需要优化,例如创建复合索引。
总结一下:
模拟优化器执行SQL查询语句的过程,来知道MySQL是怎么处理一条SQL语句的。通过这种方式我们可以分析语句或者表的性能瓶颈。如果需要具体的cost信息,可以用:
EXPLAIN FORMAT=JSON。如果觉得EXPLAIN还不够详细,可以用开启optimizer trace。
存储引擎
- 存储引擎的选择
为不同的业务表选择不同的存储引擎,例如:查询插入操作多的业务表,用MylSAM。临时数据用Memeroy。常规的并发大更新多的表用InnoDB。
- 字段定义
原则:使用可以正确存储数据的最小数据类型。为每一列选择合适的字段类型。
- 整数类型

INT有8种类型,不同的类型的最大存储范围是不一样的。性别?用TINYINT,因为ENUM也是整数存储。
- 字符类型
变长情况下,varchar 更节省空间,但是对于varchar字段,需要一个字节来记录长 度。固定长度的用char,不要用varchar。
- 不要用外键、触发器、视图
降低了可读性;
影响数据库性能,应该把把计算的事情交给程序,数据库专心做存储;数据的完整性应该在程序中检查。
- 大文件存储
不要用数据库存储图片(比如base64编码)或者大文件;
把文件放在oss或者相关平台上,数据库只存储url,在应用中配置相关地址或者节点。
- 表拆分或字段冗余
将不常用的字段拆分出去,避免列数过多和数据量过大。
比如在业务系统中,要记录所有接收和发送的消息,这个消息是XML格式的,用blob或者text存储,用来追踪和判断重复,可以建立一张表专门用来存储报文。
优化体系

除了对于代码、SQL语句、表定义、架构、配置优化之外,业务层面的优化也不能忽视。举两个例子:
1)在某一年的双十一,为什么会做一个充值到余额宝和余额有奖金的活动,例如充300送50?
因为使用余额或者余额宝付款是记录本地或者内部数据库,而使用银行卡付款,需要调用接口,操作内部数据库肯定更快。
2)在去年的双十一,为什么在凌晨禁止查询今天之外的账单?
这是一种降级措施,用来保证当前最核心的业务。
3)最近几年的双十一,为什么提前个把星期就已经有双十一当天的价格了?预售分流。
在应用层面同样有很多其他的方案来优化,达到尽量减轻数据库的压力的目的,比如限流,或者引入MQ削峰,等等等等。
为什么同样用MySQL,有的公司可以抗住百万千万级别的并发,而有的公司几百个并发都扛不住,关键在于怎么用。所以,用数据库慢,不代表数据库本身慢,有的时候还要往上层去优化。
当然,如果关系型数据库解决不了的问题,我们可能需要用到搜索引擎或者大数据的方案了,并不是所有的数据都要放到关系型数据库存储。
这是优化的层次,如果说遇到的一个具体的慢SQL的问题,我们又应该怎么去优化呢?比如有人给你发来一条SQL,你应该怎么分析?
分析查询基本情况
涉及到表结构,字段的索引情况、每张表的数据量、查询的业务含义。
这个非常重要,因为有的时候你会发现SQL根本没必要这么写,或者表设计是有问题的。
找出慢的原因
1、查看执行计划,分析SQL的执行情况,了解表访问顺序、访问类型、索引、扫描行数等信息。
2、如果总体的时间很长,不确定哪一个因素影响最大,通过条件的增减,顺序的调整,找出引起查询慢的主要原因,不断地尝试验证。
找到原因:比如是没有走索引引起的,还是关联查询引起的,还是 order by引起的。找到原因之后:
对症下药
- 创建索引或者联合索引
改写SQL
这里需要平时积累经验,例如:
- 使用小表驱动大表
- 用 join 来代替子查询
- not exist 转换为 left join is NULL 或者 or改成union
- 使用 UNION ALL 代替 UNION ,如果结果集允许重复的话
- 大偏移的 limit ,先过滤再排序。
如果SQL本身解决不了了,就要上升到表结构和架构了。
- 表结构(冗余、拆分、not null等)、架构优化。
- 业务层的优化,必须条件是否必要。
如果没有思路,调优就是抓瞎,肯定没有任何头绪。

此处评论已关闭